论文信息
Continual Learning of a Mixed Sequence of Similar and Dissimilar Tasks
- 会议:NIPS 2020
- 作者:
- Zixuan Ke:伊利诺伊大学芝加哥分校,博士生,后者的学生。
- Bing Liu:伊利诺伊大学芝加哥分校,教授。他是《终身机器学习》的作者,我有系列读书笔记。
- Xingchang Huang:苏黎世联邦理工大学,博士生。
一、场景
本文的场景就是普通的持续学习,但与其他文章不同的是,其他文章通常只关注如何解决灾难性遗忘,本文认为除了解决灾难性遗忘,还有很多其他的事情要做。
假设已学完任务 \(1, \cdots, t-1\),准备学 \(t\)。以作者的理解,对旧任务 \(t_{old}\) 的处理是有区别的:
- 如果 \(t_{old}\) 与 \(t\) 相似,则二者的知识应相互迁移:
- 前向迁移(Forward Transfer):用 \(t_{old}\) 学到的知识帮助新任务 \(t\);
- 后向迁移(Backward Transfer):\(t\) 学到的知识反过来更新旧任务;
- 如果 \(t_{old}\) 与 \(t\) 不相似,则二者蕴含的知识也是不交叉的,所以都应该记住,即在学习新任务 \(t\) 时避免遗忘 \(t_{old}\) 的知识。
而其他文章将其一视同仁,都化为第二种情况,干脆都别忘了。
迁移学习要求两个领域有相似性(见《终身机器学习》第二章笔记),作者如此分成相似与不相似的任务,前者应用迁移学习,所以本文是一篇典型的持续学习与迁移学习结合的文章。
如果任务 \(1,\cdots, t-1\) 都属于作者描述的不相似的任务,那么作者的方法就相当于其他文章了。所以本文也可以看作普通持续学习场景的推广:普通场景任务各不相似,而本文允许 “Mixed Sequence of Similar and Dissimilar Tasks”。
注意本文的场景必须是任务增量(文中称 Task Continual Learning, TCL),任务标识 \(t\) 随数据一并给出。类别增量一般每次来的是不同的类,因此很少会出现相似的情况。
二、模型
本文模型称为 CAT(Continual learning with forgetting Avoidance and knowledge Transfer)。它由三部分组成:
- 知识库(KB):是一个网络,权重中存储知识,是模型的主要部分。输入即原始输入 \(x\),输出为 \(x\) 的一个 Embedding,其后可接分类器分类。 记号:\(k_l\) 为第 \(l\) 层神经元个数,\(w_l\) 表示第 \(l\) 层到第 \(l+1\) 层的连接权重;\(g_l\) 表示损失函数在权重 \(w_l\) 上的梯度,二者都是 \(k_l \times k_{l+1}\) 矩阵;\(h_l\) 表示一个输入 \(x\) 在第 \(l\) 层的输出,是 \(k_l\) 维向量。
- 任务 Mask(TM):为 KB 网络每一层神经元(不是权重)提供 mask,标识了对当前任务的重要程度,它是二值的 0,1。 记号:\(m_l^{(t)}\) 表示任务 \(t\) 第 \(l\) 层的 mask,是 \(k_l\) 维向量。它起到了选择子网络的作用,注意有时我们想要整个网络,则不允许它起作用(或全设为1)。具体的选择作用表现在两个方面:
- 选择每一层的输出:一个输入 \(x\) 在通过网络得到 \(h_l\) 后,还要调整 \(h_l \otimes = m_l\)(效果是把一些输出值置为0),才能继续通过下一层;(最终,加了 mask 后最后一层的输出可看成针对任务 \(t\) 的特征)
- 选择更新的权重:选择了输出后,未被选中的神经元后面连接的权重就不必更新了。做法是先将 mask 向量扩展(与 broadcast 类似)为形状同 \(w_l\) 的 \(k_l \times k_{l+1}\) 矩阵,再调整梯度 \(g_l \otimes = (1-m_l)\)(效果是把置0的神经元后面权重的梯度置为0)。
- 知识迁移 Attention(KTA):是一个使用了简单的 Soft Attention 机制的网络,负责知识迁移(参考此文章),其目的是把相似任务的结果融合并迁移到新任务上。输入为 \(x\) 过任务 \(i_{sim}\) mask 的一系列特征 \(h_{mask}^{(i_{sim})}\),输出它们的某个线性组合,其后可接分类器分类:
系数即 Attention 得分:
\[a^{\left(i_{s i m}\right)}=\operatorname{softmax}\left(\frac{\left(e_{K T A}^{(t)} \theta_{q}\right)\left(\left\{h_{\operatorname{mask}}^{\left(i_{s i m}\right)}\right\} \theta_{k}\right)^{\top}}{\sqrt{d_{k}}}\right)\]参数有公共的 \(\theta_k,\theta_q,\theta_v\) 和 task-specific 的 \(e_{KTA}^{(t)}\)。Attention 机制有参数少的特点,这些参数存储了更多的知识迁移的经验。
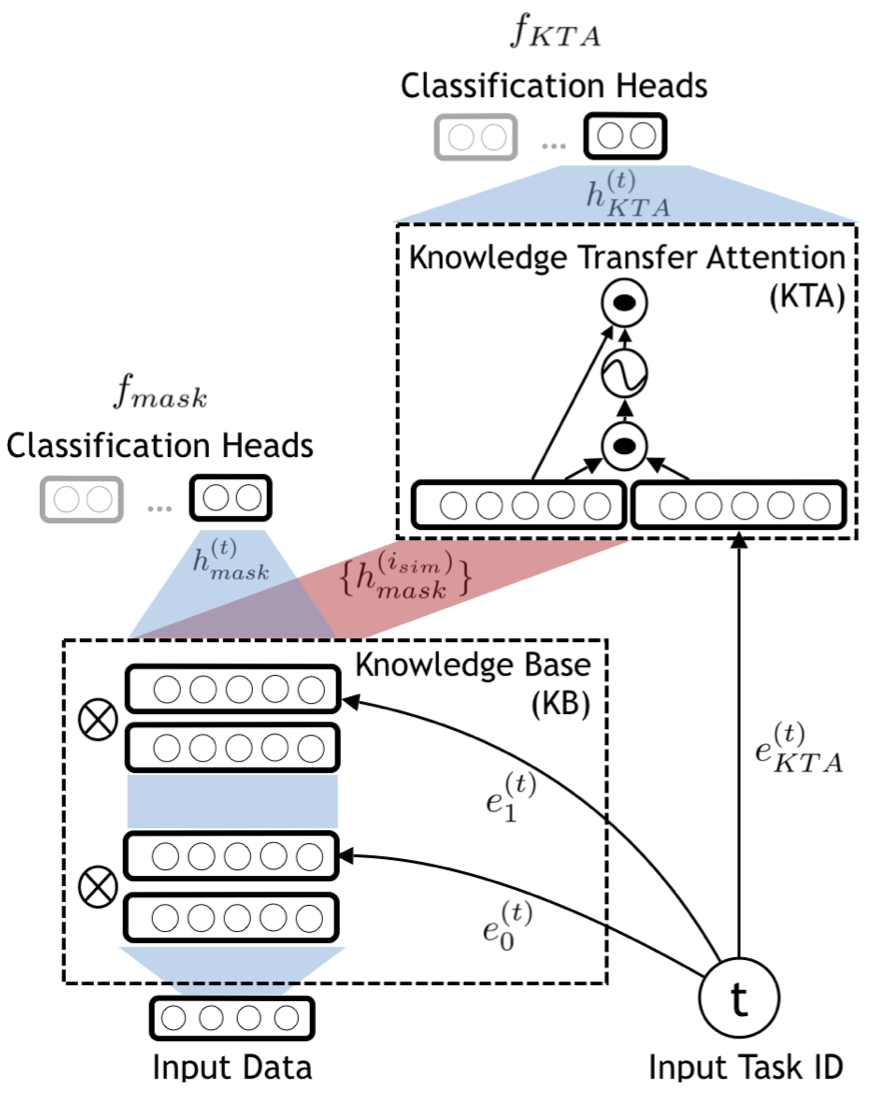
模型如图所示,主网络为 KB + KTA,TM 是嵌入在 KB 里的一个挂件。该网络在完全不需要知识迁移的时候使用 KB 的 Embedding 后接分类器分类,而需要迁移的时候将 KB 的 Embedding 再通过 KTA 得到进一步的 Embedding 后接分类器分类。
由于是任务增量学习,分类问题是几分类是已经知道的,所以分类头的形状是提前固定的。
Task Embedding
每个任务标识 \(t\) 对应一些 Embedding,它不是输入 \(x\) 的 Embedding,称为 Task Embedding。这些 Embedding 提供了“第几个任务”这种信息,是学习出来的,属于 task-specific 的网络参数,在本文中有两类:
- \(e_l^{(t)}\)(合称 \(e^{(t)}\)):用于生成 KB 第 \(l\) 层的任务 mask \(m_l^{(t)}\)。二者对应关系为 \(m_{l}^{(t)}=\sigma\left(s e_{l}^{(t)}\right)\)(\(s\) 为超参数),大于 0.5 取 1,反之取 0。
- \(e_{KTA}^{(t)}\):用于输入给 KTA,辅助计算 Attention 得分,其完成知识迁移。
模型输入不只有 \(x\),还有任务 ID \(t\),这正是任务增量学习的设定。如上图右下角所示,任务标识\(t\)先生成两种 Task Embedding,箭头分别指向 KB 和 KTA。
三、测试过程
经过 \(T+1\) 个任务的训练,训练过程已训练好如下参数或了解到如下信息:
- \(\theta^{(T)}\),它包含所有与任务无关的网络参数,如 KB 的权重,KTA 的 \(\theta_k,\theta_q,\theta_v\) 以及两个分类头的权重。在训练时,它们不断更新,只用最后任务 \(T\) 的结果;
- 每个任务与之前任务的相似性判断结果:每个任务都有两个集合 \(\tau_{sim}, \tau_{dis}\) 分别表示相似任务与不相似任务;
- 每个任务 \(t\) 的 Task Embedding \(e^{(t)}\) 和 \(e_{KTA}^{(t)}\)(后者有的可能没有,也不需要,见下节tip),前面说过它们是 task-specific 的参数。
测试过程:新来一个测试数据 \(x\) 及其任务ID \(t\):
- 如果有前面的任务与之相似(\(\tau_{sim}\neq \varnothing\)),则 \(x\) 通过 KB 在 \(\tau_{sim}\) 任务上的 mask 得到一系列特征 \(h_{mask}^{(i_{sim})}\),让它们过 KTA 和后面的分类头,得到分类结果;
- 如果没有一个相似,则 \(x\) 通过 \(e^{(t)}\) 生成的该任务的 mask,得到最后一层特征 \(h_{mask}^{(t)}\),再通过 KB 后面的分类头,得到分类结果。
四、训练过程
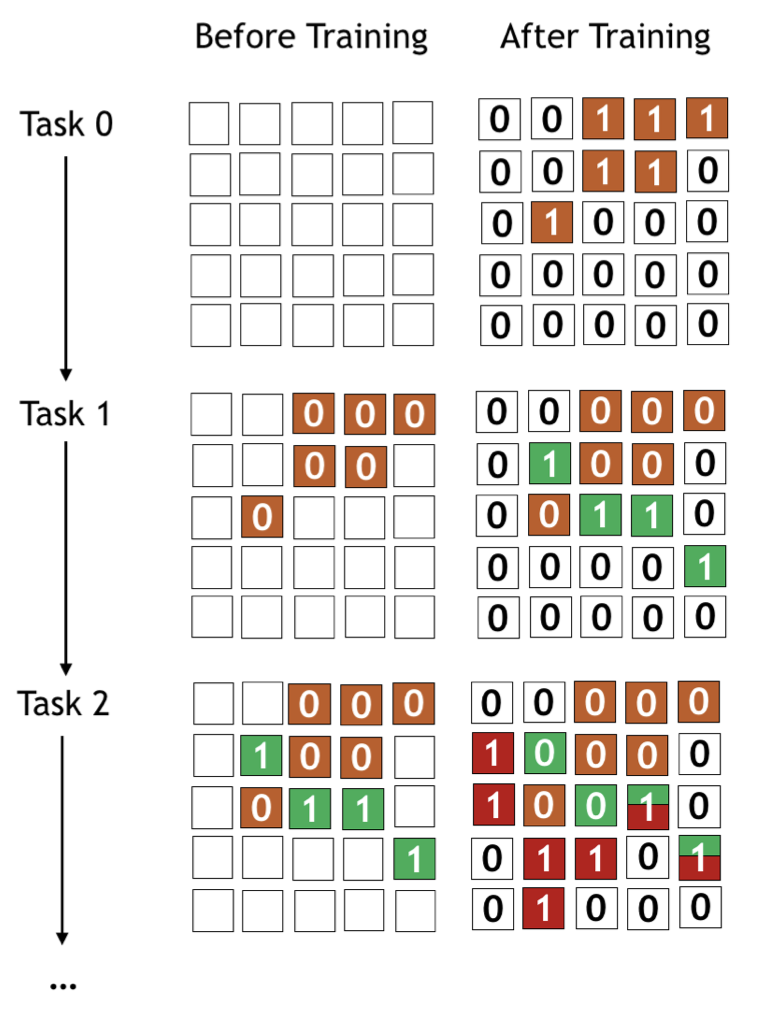
任务 0:直接训练 \(f_{mask}\),即 KB + TM + 后面的分类头:
- 数据:\(D_{train}^{(0)}\)
- 损失函数:\(\frac{1}{N_{0}} \sum_{i=1}^{N_{0}} \mathcal{L}\left(f_{m a s k}\left(x_{i}^{(0)} ; \theta_{m a s k}\right), y_{i}^{(0)}\right)\)
- 训练方式:因为是第一个任务,随机初始化
- 要用的结果:训练得到的 KB + 分类头权重 \(\theta^{(0)}\),任务 0 的 Task Embedding \(e^{(0)}\)(对应的任务 mask \(m^{(0)}\) 如图右上)
任务 1:首先判断它与任务 0 是否相似。做法是比较两个模型 \(f_{\varnothing}, f_{0\rightarrow 1}\) 的效果:
先训练参考模型(Reference Model) \(f_{\varnothing}\),即对任务 1 从头开始训练的 KB + 后面的分类头:
- 数据:\(D_{train}^{(1)}\)
- 损失函数:\(\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} \mathcal{L}\left(f_{\varnothing}\left(x_{i}^{(1)} ; \theta_{\varnothing}\right), y_{i}^{(1)}\right)\)
- 训练方式:单独复制出来一份 KB(之前的 KB 是主要的东西,不能覆盖掉),随机初始化
- 要用的结果:用验证集 \(D_{val}^{(1)}\) 测试效果
再训练迁移模型(Transfer Model) \(f_{0\rightarrow 1}\),即参考模型中的 KB 部分不用从头训,直接用针对任务 0 的特征——将训练数据过任务 0 mask 最后一层的输出,只训练后面的分类头。这件事可以等价地看成固定之前训练的任务 0 的 KB + mask:
- 数据:\(D_{train}^{(1)}\)
- 损失函数:\(\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} \mathcal{L}\left(f_{0\rightarrow 1}\left(x_{i}^{(1)} ; \theta_{0\rightarrow 1}\right), y_{i}^{(1)}\right)\)
- 训练方式:固定 KB + mask 部分的权重,分类头随机初始化
- 要用的结果:同上
如果迁移模型比参考模型效果好,任务 1 用 0 的知识都比它自己努力学习知识要好,那么有充分的理由说 0 里包含了与 1 相似的知识。相似与否,决定了任务 1 该如何训练:
若任务 1 与任务 0 不相似,则应该走防止遗忘的路线。先用任务 0 的 mask 屏蔽掉对任务 0 重要的权重,训练任务 1:
- 数据:\(D_{train}^{(1)}\)
- 损失函数:\(\frac{1}{N_{1}} \sum_{i=1}^{N_{1}} \mathcal{L}\left(f_{\varnothing}\left(x_{i}^{(1)} ; \theta_{\varnothing}\right), y_{i}^{(1)}\right)\)
- 训练方式:固定 KB 属于任务 0 mask 对应的权重,训练其他部分
- 要用的结果:\(\theta^{(1)}\),\(e^{(1)}\)(此时任务 mask 如图右中,注意 \(m^{(1)}\) 与 \(m^{(0)}\) 不可能重合)
若任务 1 与任务 0 相似,则应该走知识迁移的路线。与迁移模型道理一样,也是提取任务 0 mask 最后一层输出,但这时要训练不是简单的分类头,而是作者提出的专门负责知识迁移的 KTA + 分类头。另一个不同的是,作者没有固定前面的 KTA + TM,它允许被梯度回传训练,一是为了得到 \(e^{(1)}\)(这一步必须有,否则后面任务无法进行);二是也更新 KB,被认为是 Backward Transfer。
- 数据:\(D_{train}^{(1)}\)
- 损失函数:两部分 \(\frac{1}{N_{1}} \sum_{j=1}^{N_{1}} \mathcal{L}\left(f_{m a s k}\left(x_{j}^{(1)} ; \theta_{m a s k}\right), y_{j}^{(1)}\right)+\frac{1}{N_{1}} \sum_{j=1}^{N_{1}} \mathcal{L}\left(f_{K T A}\left(x_{j}^{(1)} ; \theta_{K T A}\right), y_{j}^{(1)}\right)\)
- 训练方式:不要屏蔽任务 0。在 $$正常训练即可
- 要用的结果:\(\theta^{(1)}\),\(\theta^,\)e^{(1)}\((此时\)m^{(1)}\(与\)m^{(0)}\(可以有重合,因为任务 0,1 是相似的),\)e_{KTA}^{(1)}$$
任务 t:相当于把任务 1 的两种情况推广到一次面对多个旧任务的情形。
首先是判断任务相似。此时要比较任务 \(t\) 与 \(0,1,\cdots,t-1\) 共 \(t\) 个任务的相似性。参考模型 \(f_{\varnothing}\)只需要一个,迁移模型则要 \(t\) 个:\(f_{0\rightarrow t}, \cdots, f_{t-1\rightarrow t}\)。得到与 \(t\) 相似与不相似的任务集 \(\tau_{sim}, \tau_{dis}\)。
对 \(\tau_{dis}\) 中的任务,要防止遗忘,它们重要的权重要统统屏蔽掉,只需要将它们的 mask 并起来即可
\[m_{l}^{\left(t_{a c}\right)}=\text { ElementMax }\left(\left\{m_{l}^{\left(i_{d i s}\right)}\right\}\right)\]对 \(\tau_{sim}\) 中的任务,要知识迁移,提取在这些任务 mask 最后一层输出,这可能涉及到多个。所幸这个 KTA 能接受多个输入,也能训练出多个 \(e^{KTA}\)。
所以,任务 t 要训练的是:
- 数据:\(D_{train}^{(t)}\)
- 损失函数:两部分 \(\frac{1}{N_{t}} \sum_{j=1}^{N_{t}} \mathcal{L}\left(f_{m a s k}\left(x_{j}^{(t)} ; \theta_{m a s k}\right), y_{j}^{(t)}\right)+\frac{1}{N_{t}} \sum_{j=1}^{N_{t}} \mathcal{L}\left(f_{K T A}\left(x_{j}^{(t)} ; \theta_{K T A}\right), y_{j}^{(t)}\right)\)
- 训练方式:屏蔽任务 \(\tau_{dis}\),其他正常训练即可
- 要用的结果:\(\theta^{(t)}\),\(e^{(t)}\),\(e_{KTA}^{(t)}\)
请注意,\(e_{KTA}^{(t)}\) 并不是所有任务都需要。如果永远没有与 \(t\) 相似的任务,那么也就无需训练它了,因为测试阶段不可能用到它。
上图最下面的两图,表示任务 2,\(\tau_{sim} = \{1\}, \tau_{dis} = \{0\}\)。请自行体会。
总结一下上面,任务 0 相当于不与前面任何相似。任务 1 由于前面只有一个,要么空集,要么全集;中间情况只有任务 2 才可能开始有。任务 0 和 1 的过程都可以统一到任务 t 的流程内。