论文信息
Representational Continuity for Unsupervised Continual Learning
- 会议:ICLR 2022 (Oral)
- 作者:
- 纽约大学、韩国科学院、清华大学智能产业研究院等
一、场景:无监督持续学习
设持续学习包含 $T$ 个任务,当前正在学习第 $\tau$ 个任务。持续学习要求不仅对新数据做Fine-tuning,还要复习过去的知识,这两部分体现在优化目标 $\mathcal{L}$ 的两项,记为
\[\mathcal{L} = \mathcal{L}^{\text{FINETUNE}} + \mathcal{L}^{\text{REVIEW}}\]我用一张表来比较有监督和无监督的区别(以分类为例):
| 有监督持续学习(Supervised CL) | 无监督持续学习(Unsupervised CL) | |
|---|---|---|
| 新来的数据 | \(\mathcal{D}_{\tau} = \{(\mathbf{x}_{i,\tau}, y_{i,\tau})_{i=1}^{n_\tau}\}\) | \(\mathcal{U}_\tau = \{(\mathbf{x}_{i,\tau})_{i=1}^{n_\tau}\}\) |
| 模型与参数 | \(X_\tau \rightarrow \mathcal{Y}_\tau\),可看成 表示函数 \(f_\Theta : X_\tau \rightarrow \mathbb{R}^D\) 和 分类器 \(h_\psi: \mathbb{R}^D \rightarrow \mathcal{Y}_\tau\) | 只有表示 \(f_\Theta : X_\tau \rightarrow \mathbb{R}^D\) |
| \(\mathcal{L}^{\text{FINETUNE}}\) | \(\mathcal{L}_{\text{SCL}}^{\text{FINETUNE}} = CE(h_\psi(f_\Theta(\mathbf{x}_{i,\tau}),y_{i,\tau})\) | $$\mathcal{L}_{\text{UCL}}^{\text{FINETUNE}}$$ |
| \(\mathcal{L}^{\text{REVIEW}}\) | 由现有的各种持续学习框架定义 | $$\mathcal{L}_{\text{UCL}}^{\text{REVIEW}}$$ |
对于不同的任务有不同的分类器(注意:$h_\psi(\cdot, \tau)$),分类器是一个比表示$f_\Theta$简单得多的网络,对每个任务 $\tau$ 都会根据当前的 $f_\Theta$ 作微调。虽然这里是有参数的,但完全可以是无参数的,如K近邻分类器。这个分类器不是持续学习的学习目标,只是模型里的一个必要的输出头。
无论有监督还是无监督,都是为了学到一个好的表示 $f_\theta$ ,但由于有监督的任务要求输出类别 $\mathcal{Y}_\tau$,不可避免地需要接一个分类器。无监督的任务虽然只需要得到表示即可,但是我们无法评估这个表示的好坏,因此一般的评估方法也是接一个分类器,以输出结果与真实类别的比较作为衡量标准,计算准确率等评价指标。这里真实类别的标签只用在评估时,没有用在训练时,损失是一种自监督的损失(self- supervised loss),这是有监督和无监督的本质区别。
设计 \(\mathcal{L}_{\text{UCL}}^{\text{FINETUNE}}\) 和 \(\mathcal{L}_{\text{UCL}}^{\text{REVIEW}}\)是设计无监督学习框架的主要任务,分别放在第二、第三部分讲述。
二、无监督模型
目前大火的无监督表示学习模型就是对比学习(Contrastive Learning)了,作者选用了其中一些比较适合的持续学习场景的模型,它们都是基于孪生网络的思想。
孪生网络(Siamese Network)是要求两个输入的网络,通过网络后分别得到这两个输入的表示。它可以看成一个网络,也可以看成两个共享权重的网络(所以叫孪生网络)。得到的两个表示一般要算一下相似度(最简单的是余弦相似度,即两个向量的夹角),这个相似度用来构造损失,具体什么样的损失由网络要完成的任务来定。任务只有一个要求——两个输入,比如判断两个图片是否是同一类,等等。

孪生网络如何用在无监督学习中呢?自然,对于一个输入 $\mathbf{x}$,无监督学习要学的表示函数就是这个孪生网络。但是它要求两个输入怎么办呢,接下来就是主要思想:这两个输入是原始输入的两个Augmentation $\mathbf{x}^1,\mathbf{x}^2$,如果这个表示认为由同一个输入 $\mathbf{x}$ 变换出来的 $\mathbf{x}^1,\mathbf{x}^2$ 是相似的,那它就是一个好的表示。因此优化目标是尽量让得到的两个表示接近,构造的损失函数也就用到了上文提到的相似度,一般来说是迫使相似度尽量大,例如
\[\mathcal{L} = - D(z_1, z_2)\]其中 $z_1, z_2$ 是 $\mathbf{x}^1,\mathbf{x}^2$ 通过孪生网络 $f$ 后的两个表示,$D$ 是余弦相似度。
SimSiam
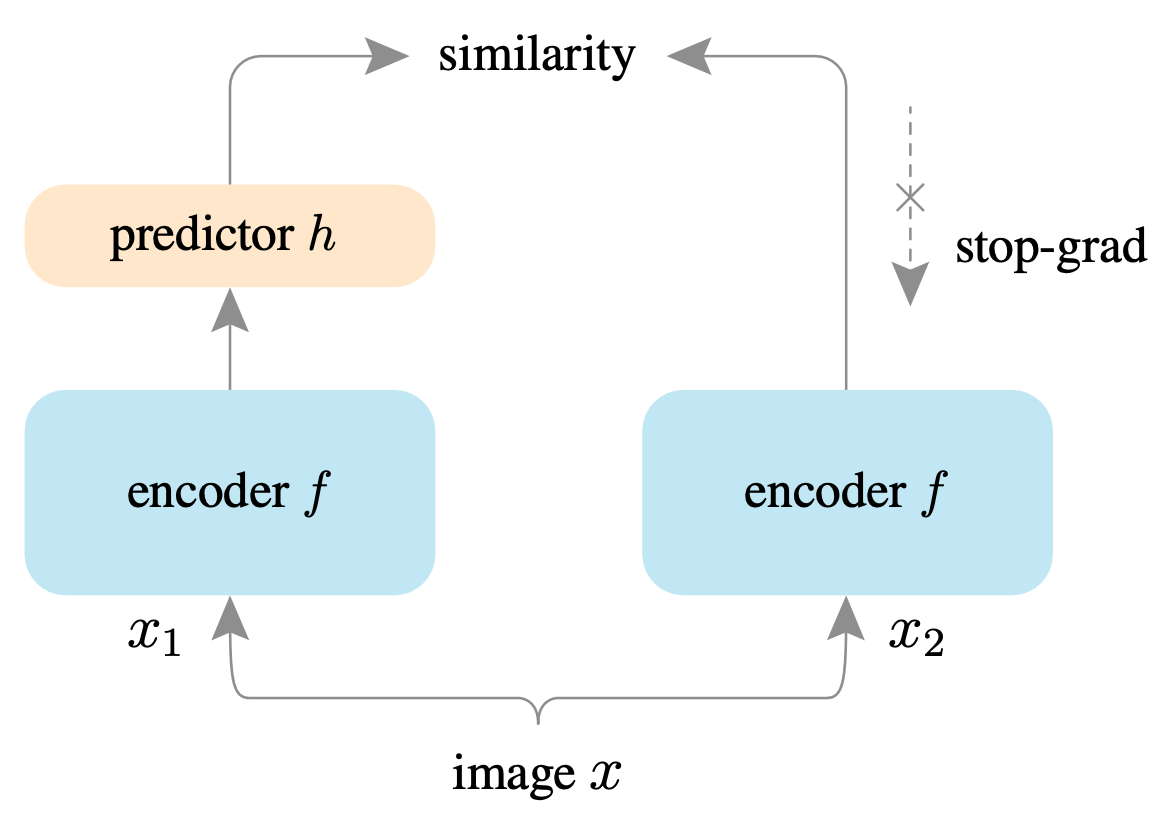
对于无监督的表示学习,Facebook何恺明、陈鑫磊等人提出了一个简单的孪生网络SimSiam,但是比上面最简单的还是多了一些东西的:它在表示网络后接了一个预测头 $h$(也是一个网络),这样两个输入就有了四个表示:$z_1 \triangleq f(\mathbf{x}_1), z_1 \triangleq f(\mathbf{x}_1), p_1 \triangleq h(f(\mathbf{x}_1)), p_2 \triangleq h(f(\mathbf{x}_2))$。最终交叉混淆处理相似度:
\[\mathcal{L} = \frac12 D(p_1, z_2) + \frac12 D(p_2, z_1)\]这个模型最重要的事情是要求把 $z_1,z_2$ 看作常数,而不是含模型参数的函数(在PyTorch里就是detach一下),记作 \(\text{stopgrad}\)。统一到本文的符号,写作:
Barlow Twins
为了得到一个好的表示,除了使同一个输入 $\mathbf{x}$ 产生的两个变换表示尽量接近,还可以使不同输入的表示尽量地远(其实这样有可能带来问题,暂且不讨论)。Facebook的另外一些人,包括Yann LeCun提出的Barlow Twins,就在损失函数中加了第二项:
\[\mathcal{L}_{\mathrm{UCL}}^{\mathrm{FINETUNE}} = \sum_i (1 - \mathcal{C}_{ii})^2 + \lambda \cdot \sum_i \sum_{j\neq i} \mathcal{C}_{ij}^2\]这个损失每次考虑多个输入 $\mathbf{x}^1, \cdots, \mathbf{x}^i, \cdots$,同样地,每个输入 $\mathbf{x}^i$ 都有两个Augmentation $\mathbf{x}^i_1,\mathbf{x}^i_2$,$\mathcal{C}_{ij}$ 就是两个输入不同变换之间的相似度 \(\mathcal{C}_{ij} = \mathcal{D}(z^i_1, z^j_2)\)。这个损失的第一项其实就是上面最简单的相似度损失(累加了多个输入的),第二项的损失给了一个可调的超参数 $\lambda$。
三、如何持续起来?
大部分持续学习模型都是针对有监督场景的,难以直接应用到无监督,但有一些确实是可以推广的。作者从三类持续学习模型各取了一个代表:
重演法:DER
重演法一般要在记忆 $\mathcal{M}$ 里存放重演数据,而有些是连同标签一起存进去,训练新任务时构造进REVIEW损失里去,这样的重演模型就不好推广到无监督。作者找到的DER(Dark Experience Replay)用不着重演数据 $x$ 的标签,而是存旧模型预测的过Softmax之前的logit $p$。防止遗忘的方法是让新模型预测重演数据的logit尽量与存的接近:
\[\mathcal{L}_{\mathrm{SCL}}^{\mathrm{DER}}=\mathcal{L}_{\mathrm{SCL}}^{\text {FINETUNE }}+\alpha \cdot \mathbb{E}_{(x, p) \sim \mathcal{M}}\left[\left\|\operatorname{softmax}(p)-\operatorname{softmax}\left(h_{\psi}\left(x_{i, \tau}\right)\right)\right\|_{2}^{2}\right]\]推广到无监督,只需将logit换成网络输出的表示:
\[\mathcal{L}_{\mathrm{UCL}}^{\mathrm{DER}}=\mathcal{L}_{\mathrm{UCL}}^{\text {FINETUNE}}+\alpha \cdot \mathbb{E}_{(x) \sim \mathcal{M}}\left[\left\|f_{\Theta_{\tau}}(x)-f_{\Theta}\left(x_{i, \tau}\right)\right\|_{2}^{2}\right]\]其实最经典的iCaRL也可以推广到无监督(它的REVIEW损失是蒸馏损失),但是有点古老了效果已达不到SOTA,所以作者没有用它。
加正则项法:SI
SI(Synaptic Intelligence)是对著名持续学习算法EWC 的改进,在EWC中,由上一个任务 $\tau-1$ 学习下一个任务 $\tau$ 时,
\[\mathcal{L}_{\mathrm{SCL}}^{\mathrm{EWC}}=\mathcal{L}_{\mathrm{SCL}}^{\mathrm{FINETUNE}}+\frac{\lambda}{2} \cdot \sum_{i} F_{i, i}\left(\theta_{i}-\theta_{\tau-1, i}^{*}\right)^{2}\]可见加的REVIEW正则项只与之前任务学到的模型参数有关,不涉及数据的标签信息,SI也是如此。因此有监督损失可以轻易推广到 \(\mathcal{L}_{\mathrm{UCL}}^{\mathrm{SI}}\)。
网络结构法:PNN
这个方法是对网络结构本身动手脚,在不同的任务阶段,网络结构是不同的,持续并不是通过添加正则项 \(\mathcal{L}^{\text{REVIEW}}\)、而是通过训练新的网络参数实现的。在这个PNN(Progressive Neural Network)中,每次新任务都会在图中右边多出一列网络出来,冻结原有的权重(虚线),只训练新的权重(实线)。
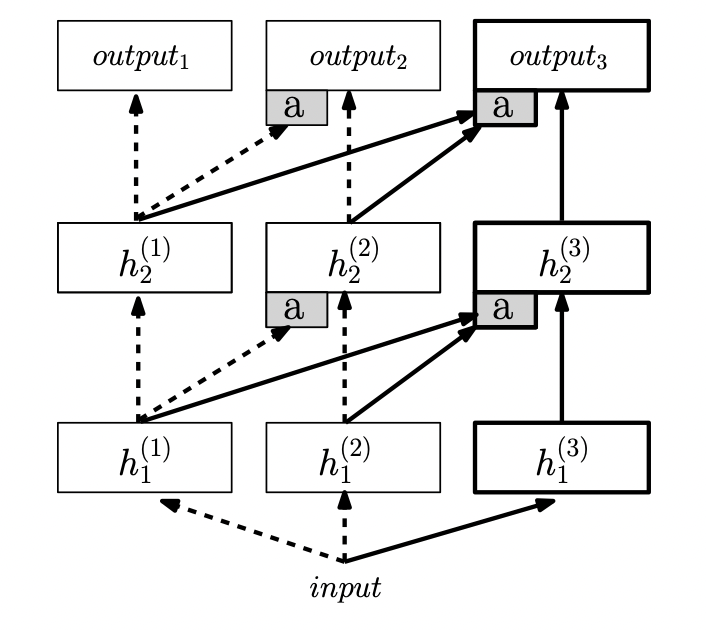
对无监督学习,只需将网络改成上节的孪生网络,此图用MLP结构,则孪生网络也用MLP即可。训练时的损失 \(\mathcal{L}_{\mathrm{UCL}}^{\mathrm{PNN}}\)就用上节的无监督损失 \(\mathcal{L}_{\mathrm{UCL}}^{\mathrm{FINETUNE}}\)。
四、Mixup技巧
作者也借鉴了Facebook实验室提出的Mixup技巧。这是一个比较直观的训练上的trick,即任取两个训练数据作线性组合,得到的这种混合数据(基本上在原始训练数据的周边)也拿去训练。机器学习理论中,用最小化由训练数据集构造的损失这种机制被称为经验风险最小化(ERM,Empirical Risk Minimization),现在这种最小化原始训练集的周边风险最小化(VRM,Vicinal Risk Minimization)。
这样做的优点显然是能提高模型的鲁棒性,所以作者拿过来用在了他的无监督损失上,这也是本文的主要创新点吧,取名为LUMP(Lifelong Unsupervised Mixup)。具体的用法是在对新数据微调的损失 \(\mathcal{L}_{\text{UCL}}^{\text{FINETUNE}}\) 中,不仅使用新数据 $x_{i,\tau}$,而使用新数据与过去知识(注意:LUMP是对DER的改进,需要记忆重演数据 $\mathcal{M}$)的混合:
\[\tilde{x}_{i, \tau}=\lambda x_{i, \tau}+(1-\lambda) x_{j, \mathcal{M}}\]。这样,无监督损失 \(\mathcal{L}_{\text{UCL}}\)不仅在\(\mathcal{L}_{\text{UCL}}^{\text{REVIEW}}\) 中考虑了过去的知识,也在 \(\mathcal{L}_{\text{UCL}}^{\text{FINETUNE}}\) 考虑了。这里也给了可调的超参数 \(\lambda\),用以trade-off持续学习模型的可塑性与稳定性。
五、实验与结论
总结一下上面提到的无监督持续学习方法,按照 \(\mathcal{L}_{\text{UCL}}^{\text{FINETUNE}}\) 分有SimSiam、Barlow Twins共2类,按照 \(\mathcal{L}_{\text{UCL}}^{\text{REVIEW}}\) 分有改造成无监督场景的SI、PNN、DER、外加作者针对DER的改进LUMP共4类,所以一共有 \(2\times 4 =8\) 个无监督持续模型。本文的实验是连同有监督的持续学习一起,对这些方法做一个对比。和其他持续学习一样,评价指标有各任务平均准确率 \(A = \frac1T \sum_{\tau=1}^T acc_\tau\) 和 各任务平均遗忘程度 \(F = \frac1{T-1}\sum_{\tau=1}^{T-1} \max_{1\leq t \leq \tau}(acc_t - acc_\tau)\) 。
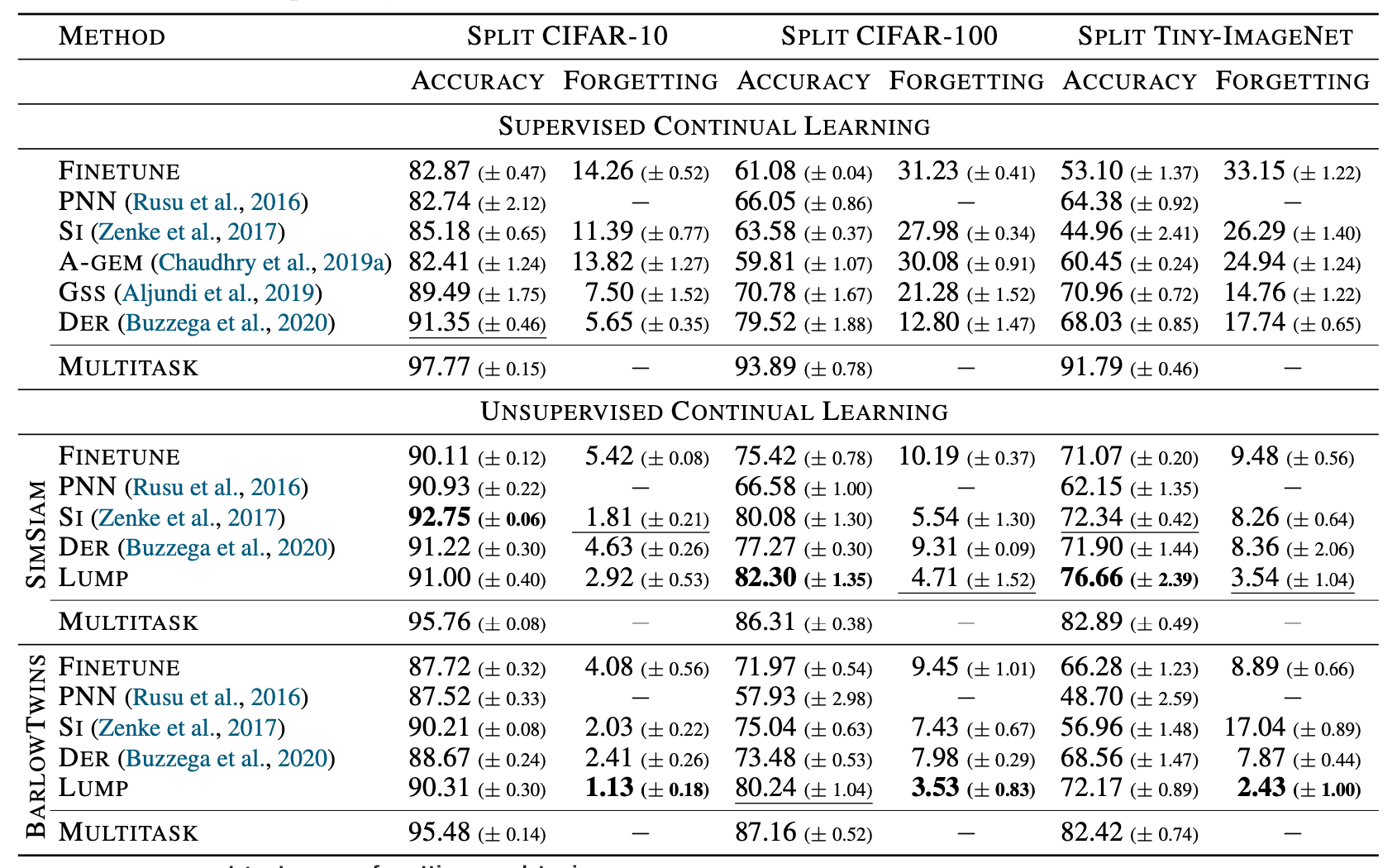
应注意这里有监督和无监督实验的关系是:数据集是相同的,无监督就是直接去掉了有监督数据集的标签。作者的实验居然发现少了标签信息的无监督学习,效果都比有监督好!可以看到,在这个实验结果中无监督基本是碾压有监督的,根据我的猜测,可能是因为无监督学习使用了两个Augmentation起了主要作用,很大程度上丰富了训练数据。本文提出的LUMP效果也要高于其他方法,可能也是Mixup技巧引入了更多训练数据导致的。小伙伴们觉得这个实验公平吗?