论文信息
Variational Continual Learning
- 会议:ICLR 2018
- 作者:剑桥大学
Improving and Understanding Variational Continual Learning
- 发表:ArXiv 2019
- 作者:剑桥大学
贝叶斯观点下的监督学习
贝叶斯学派将模型参数 \(\theta\) 当作随机变量。普通的贝叶斯监督学习只需要求一次后验分布(即一次推断),而对在线学习/持续学习场景,数据是分批来的,需要根据如下迭代公式多次求后验分布:
\[\begin{align}p(\theta\mid D_{1:t}) &= p(\theta \mid D_{1:t-1},D_t) \\&\propto p(\theta \mid D_{1:t-1})p(D_t\mid D_{1:t-1},\theta)\\&= p(\theta \mid D_{1:t-1})p(D_t\mid \theta) \end{align}\] \[p(\theta\mid D_1) = p(\theta)p(D_1\mid \theta)\]\(p(\theta)\) 为先验分布。其中最后一个等号是假设了 \(D_t\) 与 \(D_{t-1}\) 独立。
求出后验分布后,测试阶段用推断算法作预测:
\[p\left(y^*\mid \boldsymbol{x}^*, D_{1: t}\right)=\int q_t(\theta) p\left(y^* \mid \theta, \boldsymbol{x}^*\right) \mathrm{d} \theta\]近似算法
用迭代公式 \(p(\theta\mid D_{1:t})=p(\theta \mid D_{1:t-1})p(D_t\mid \theta)\) 直接计算后验分布是很难的,需要近似算法来计算。这里近似算法的通用框架是:引入一个 \(q_t(\theta)\) 作为后验分布的近似 \(p(\theta\mid D_{1:t})\),初始化与其相同,但迭代公式改为近似公式:\(p(\theta\mid D_{1:t})=proj(p(\theta \mid D_{1:t-1})p(D_t\mid \theta))\),\(proj(p)\) 代表近似计算 \(p\)。
不同的 \(proj\) 代表了不同的近似算法。作者列举了四个:
- Laplace 近似:用一个正态分布来近似。只需求出均值、方差两参数即可;
- 变分法近似:从一个(概率)函数族 \(Q\)中找一个最接近的作为近似。科普一下,变分问题是指泛函(函数的函数)的极值问题。
- Moment Matching:是一种最优传输算法。最优传输目的是将一个普通的分布映射到另一个分布,使其传输代价最小。Moment Matching 想让分布映射到指数族分布的组合;
- 重要性采样:一种采样方式
在在线学习中,每一步迭代都是用同一分布的一部分数据更新。以上四种对应的迭代更新算法,都有相应的工作:
- Laplace Propagation
- Online VI / Streaming Variational Bayes
- Assumed Density Filtering
- Sequential Monte Carlo
本文选用的是变分法近似,变分法常用 KL 散度作为分布间相似程度的度量:
\[q_t(\theta) = \arg\min_{q(\theta)\in Q} KL(q(\theta)\|\frac1{Z_t} q_{t-1}(\theta)p(D_t\mid \theta)), t = 2,\cdots, T\]\(1/Z\) 是归一化常数。
这等价于训练时在最大化似然的损失函数中加入 KL 项:
\[\mathcal{L}_t\left(q_t(\theta)\right)=\sum_{n=1}^{N_t} \mathbb{E}_{\theta \sim q_t(\theta)}\left[\log p\left(y_t^{(n)} \mid \theta, \mathbf{x}_t^{(n)}\right)\right]-KL\left(q_t(\theta) \| q_{t-1}(\theta)\right)\]本文中取 \(Q\) 为简单的正态分布的乘积族(称为 Gaussian mean-field Approximation):\(q_t(\theta)=\prod_{d=1}^D \mathcal{N}\left(\theta_{t, d} ; \mu_{t, d}, \sigma_{t, d}^2\right)\)(对应地 \(q_0(\theta)\) 应初始化为正态分布)。这样,泛函优化转化为对正态分布参数 \(\mu_{t, d}, \sigma_{t, d}^2\) 的优化。注意,模型参数 \(\theta\) 不是优化的目标,贝叶斯方法从来不是更新 \(\theta\) 的确定值,它只是分布的自变量。
训练时,使用了 Monte Carlo(类似随机梯度下降)处理似然项 \(\sum_{n=1}^{N_t}\) 太大的情况,也用了再参数化(reparameterization)技巧减少参数量。有空我开一篇笔记总结一下训练这种损失函数对技巧。
防止遗忘的手段:Coreset
持续学习与在线学习的区别是不同任务之间的数据不服从同分布假设,必须要采取防止遗忘的手段。在非贝叶斯框架下,防止遗忘的手段有重演、正则化、网络结构三种方法;在贝叶斯框架下,也需要发展出类似的手段。
本文提出了一个简单的防止遗忘的方法 —— coreset,直译为核心数据集,是对数据做操作的,类似于重演数据的方法。
每个任务有数据 \(D_t\),也有一个 coreset \(C_t\)。\(C_t\) 需要迭代地构造出来,作者给了几种简单的方法:
- 随机取 \(D_t\) 中 K 个点加到 \(C_{t-1}\);
- K-center 算法,确保 K 个点平摊在 \(D_t\) 中,面面俱到;
- 其他启发式算法……
这里迭代求后验 \(p(\theta\mid D_{1:t}/C_t)\) 的近似,而不是 \(p(\theta\mid D_{1:t})\)。求出了 \(p(\theta\mid D_{1:t}/C_t)\) 后,可以继续算出 \(p(\theta\mid D_{1:t})\),这才是我们要用的。
\(p(\theta\mid D_{1:t}/C_t)\) 的迭代公式推导:
\[\begin{align} p(\theta|D_{1:t}/C_t) &= p(\theta|D_{1:t-1}\cup D_t/C_t\cup C_{t-1}/C_{t-1})\\&=p(\theta|D_{1:t-1}/C_{t-1} ,D_t\cup C_{t-1}/C_t)\\&\propto p(\theta|D_{1:t-1} /C_{t-1})p( D_t \cup C_{t-1}/C_t|\theta)\\ \end{align}\]以 \(\tilde{q}(\theta)\) 表示 \(p(\theta\mid D_{1:t}/C_t)\) 的近似,使用变分法近似:
\[\tilde{q}_t(\theta) = \arg\min_{q(\theta)\in Q} KL(q(\theta)\|\frac1{Z_t} \tilde{q}_{t-1}(\theta)p(D_t \cup C_{t-1}/C_t\|\theta)), t = 2,\cdots, T\]在测试时,才求出 \(p(\theta\mid D_{1:t})\):
\[p(\theta\mid D_{1:t})= p(\theta\mid D_{1:t}/C_t\cup C_t)=p(\theta\mid D_{1:t}/C_t,C_t)\propto p(\theta\mid D_{1:t}/C_t)p(C_t\mid \theta)\]剪枝效应
论文的实验考虑了两个数据集:Split MNIST 和 Permuted MNIST,分别对应持续学习的类别增量和任务增量场景。实验将 VCL、VCL+Coreset 与其他持续学习方法对比平均准确率等指标,也对比了 Coreset 不同的大小的影响。
在该团队的另一篇论文 Improving and Understanding Variational Continual Learning 中,提到了一个很有趣的事情:剪枝效应(pruning effect)——每个任务训练时会只用极少部分的神经元,剩下的神经元看起来被 prune 掉了。被 prune 掉的神经元表现出两方面:
- 前面连接的权重的(边缘)分布在更新时几乎不动;
- 后面连接的权重的(边缘)分布几乎为 0 的单点分布(密度为 delta 函数),使得它对最后结果的影响几乎为 0。
具体来说,在 Split MNIST 实验(一次来两个新类)中:
- 选用了包含一个 200 神经元隐藏层的网络;
- 发现每来一个新任务,只用一个神经元;
- 有无 coreset 不影响剪枝效应。
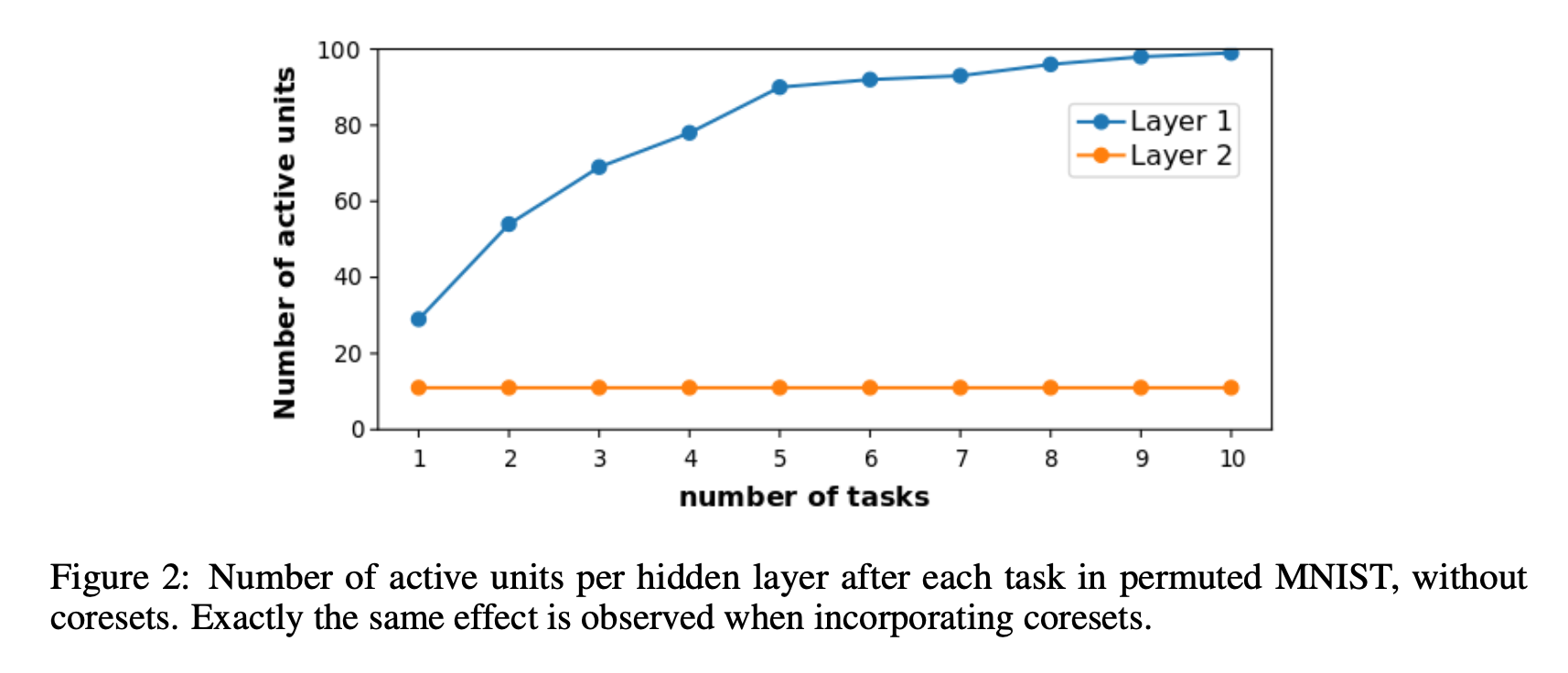
在 Permuted MNIST 实验(一次 10 个类都有)中:
- 选用了包含两个 200 神经元隐藏层的网络;
- 发现每来一个新任务,下层隐藏层神经元一次只用一部分神经元,而上层只用到 11 个神经元,且每个任务都用这 11 个神经元。见下图。
- 有无 coreset 不影响剪枝效应。
对该现象的解释,作者认为这个效应是 VCL 特有的,是 “变分” 导致的,即那个 KL + 似然的损失函数导致的。作者从这个函数给出了直观的解释,没有严格推导,但我觉得很玄学,就不再说了。
这个剪枝效应对持续学习是好是坏?作者倾向于认为是好,原因有二:
- 每次只用一小部分神经元,自动地为后面的任务预留了空间,解决了持续学习模型 “容量” 不够的问题;
- 天然地完成了 forward / backward transfer。作者解释这个主要在 Split MNIST 体现:假设任务 1 只用了第 1 个隐藏层神经元,任务 2 只用了第 2 个。第 1 个神经元更新输出到 2 的权重会帮助任务 2 的分类;第 2 个神经元更新输出到 1 的权重会帮助任务 1 的分类。