本文介绍快慢网络式持续学习,即构建一个两部分的网络,慢网络负责粗略特征的学习,快网络负责任务特定的细节特征的学习。它们适用于 TIL、CIL 场景不限。它们都借鉴自神经科学中的互补学习系统(complementary learning systems, CLS)理论。
快慢网络一般要利用人为的规定来区分开,通常是规定训练方式,让二者的训练速度有差别:即让一个学得快,另一个学得慢。
论文信息
DualNet: Continual Learning, Fast and Slow
- 会议:NIPS 2021
- 作者:新加坡管理大学
Learning Fast, Learning Slow: A General Continual Learning Method based on Complementary Learning System
- 会议:ICLR 2022
- 作者:荷兰四维图新
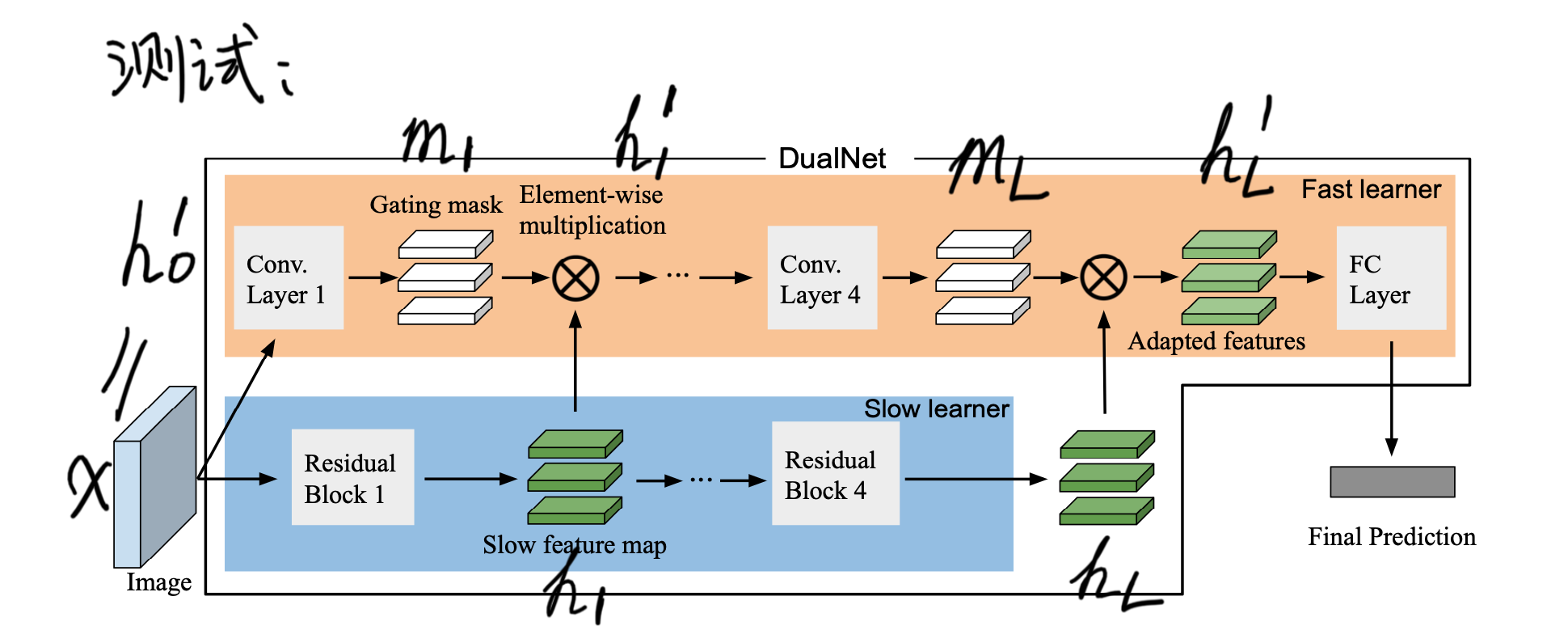
DualNet
此方法应当看成重演方法,它主要的机制还是重演数据,只是将其用在了加的自监督正则项,由此附赠引入了一块附带的网络,即文章中的“慢”网络。
快网络就是主网络、原来的特征提取器;慢网络是逐层附加到快网络上的,起到了逐层修改快网络特征 \(h_l\) 的作用(修改后的 adapted feature 为 \(h'_l\))。
训练时,除了新任务的分类损失和常规的重演损失,还在慢网络上使用重演数据的 BarlowTwins 自监督损失进行自监督学习,即对一批重演数据作两种不同的变换 A,B,使得同一个样本变换后过完网络也尽量相似,不同的样本尽量不相似(参见之前无监督持续学习的笔记)。
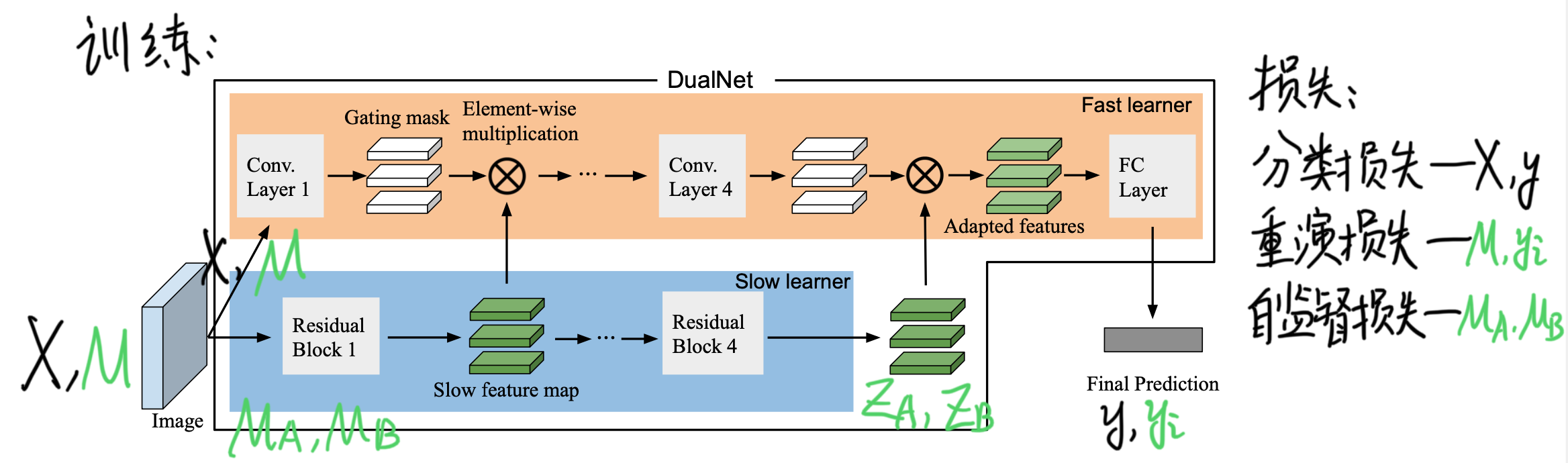
区分快慢网络的方法:训练方式上,慢网络用的是 look-ahead 策略,即快网络每更新 K 步,慢网络才更新一步。
Learning fast, Learning slow
此方法的快慢网络是独立于主网络的两套网络,且二者是并列关系。这就是一个基于知识蒸馏的重演方法,特殊在知识蒸馏参考的网络有两个——快慢网络,训练时根据每个 batch 的具体情况选择其中一者加到蒸馏损失中(选择的方法可以是实用主义的,哪个效果好选哪个),蒸馏损失用于防止遗忘。在主网络一步更新后,快慢网络也要更新,用的是一种蒸馏网络的方法:exponential moving average(EMA)。
区分快慢网络的方法:快慢网络更新时,让其有一定的几率强制不更新,以不更新的几率大小来区分,快网络不更新的几率要小一些。

借鉴
应用到任务相似性的方法
我希望从快慢网络式持续学习中得到启发,结合到基于任务相似性的方法。落脚点暂定任务分组的 mask 方法(见 Task Grouping 论文 PPT 最后一页:应用到持续学习)。
快慢网络的方法应当看成一种解决遗忘的方法,它与基于任务相似性的方法其实是独立的,二者可以独立地共存于一个模型中,即在上述两个模型中引入任务相似性机制。参考思路:
- 在 DualNet 快慢网络上引入任务分组的 mask,由于网络分成了两部分,mask 怎么分配到两部分也要作细节设计;
- 在 Learning fast, Learning slow 的主网络上引入任务分组的 mask。
这种结合方式比较生硬,最好是从思想上结合。快慢网络方法最重要的思想是区分网络各部分的训练速度。这一点我认为可以结合于任务相似性上:首先,不硬性地隔离参数训练(即某些参数硬性固定不更新),而是允许所有参数更新;在此逻辑基础上,把任务相似度这一信息用在训练速度上。参考思路:
- 相似任务分组 mask 的部分快一点,不相似的慢一点;
- 借鉴 Learning fast, Learning slow 的方法,网络扩张法:每个任务分组给一个网络,有多个网络而不是两个快慢网络。新加入的任务分组开辟新的网络。选择蒸馏损失时的网络的标准、更新几率都使用任务相似度。甚至可以把选择网络也改成软的:相似度与蒸馏损失项的正则化系数成正比。
## 两个网络,训练信息更多
在快慢网络的方法中,有至少两套网络,直观上能获得加倍的信息(如果两套网络比较独立),很适合使用这种方法。这些方法直接套用到快慢网络中是没有意义的,必须对快慢网络有所区别地获取信息,否则不如直接不分快慢网络,而构造一个参数量二倍的网络。如何有区别地获取训练信息是重点。
在上面的两种快慢网络方法中,Learning fast, Learning slow 看起来是不太适合的,因为是快慢网络是跟在主网络屁股后面训练的,三个网络本质上不独立。但是,本质上将训练轨迹在折线内测多找了几个参数点(形成了月牙形区域),也是多了一些信息的,例如用在OGD,可以把快慢点连起来多一些给 Schmidt 正交化的梯度。
DualNet 中,快慢网络是以参与构造损失函数的不同项区分的,所以最好利用损失这一训练信息,使用其他的会显得生硬。训练任务 t-1 时,得到的损失函数分成了两部分,一部分反映了 1,…,t-1 的信息,另一部分自监督损失反映了 1, …, t-2 的信息。自监督损失是用计算的 Barlow Twins 矩阵整合出来的,可以使用该矩阵作为训练信息,而不是自监督损失。