开新坑了。我的研究方向是持续学习,这就是一本少见的系统讲持续学习的书,作为稀缺的资源我也把它涉猎一下吧。此书不够前沿,我不打算特别细致地读,这些笔记也只是总结书的逻辑和一些亮点。
纵观全书,感觉就是一篇写的很长的综述,甚至和综述论文结构都是一样的。至于是不是在水,等我看完之后评价。后面几章格外关注 NLP 和强化学习领域,暂时不打算看,我计划是看到第 5 章。
书籍信息
Lifelong Machine Learning (Second Edition)
- 出版年月:2018 年 8 月
- 作者:
- Zhiyuan Chen: Google 研究员,可能是后者的学生
- Bing Liu:伊利诺伊大学芝加哥分校,教授
到底是持续学习?还是终身学习?
有没有感觉人工智能这个领域,好多词语很混乱诶,分不清!就我所知持续学习还有另一个名字——终身学习,而且目前论文也会经常出现这个词!本书给了一个统一的逻辑区分它们,本章只讨论一下终身学习和持续学习,其他的词汇在第 2 章专门讨论。
持续学习和终身学习的思想是一样的,区别仅在于名词出现的早晚:终身学习在 1996 年就由 Thrun 提出来了,之后的文章也用终身学习这个词;直到近些年深度学习社区才开始使用持续学习这个词,并且把关注点转移到了灾难性遗忘问题上。
目前只看这两个词,其他的相关术语在本书第二章专门介绍。所以终身学习的涵盖范围(在方法上,而不是概念上)比持续学习广很多,本书的标题就是终身学习,持续学习只是作为其中的一个章节。 除基于深度学习的持续学习以外,终身学习还涉及很多类的方法与领域,散布在本书的各章:
- 第 3 章:终身的监督学习(Lifelong Supervised Learning)
- 第 4 章:持续学习(Continual Learning)
- 第 5 章:开放世界学习(Open-World Learning)
- 第 9 章:终身强化学习(Lifelong Reinforcement Learning)
在 1.3 节给出了整个终身学习各个领域的简要历史,可以参考。所以,看看这本书不仅能把 AI 这类思想来龙去脉搞清楚,兴许也能从老终身学习方法中借鉴到一些灵感呢!另外,以作者做研究的角度,终身学习出于很多原因在之前一直不温不火,而且更多地用在 NLP 上(不像现在持续学习多数用图像数据集),见第 8-9 页。
又是被啰嗦过一万遍的背景!
为什么要终身学习?这种问题每看一篇持续学习的论文都要七嘴八舌地搬出一套逻辑,都看烦了诶!但我还是想说一下作者的逻辑!
终身学习的反义词,作者选用的词语是独立式学习(isolated learning)。纵观本书开头的长篇大论,就是从三个方面阐述了持续学习的重要性:
- 世界:世界上万事万物都是有联系的;
- 人类:人类的学习从来不是独立地从头学习,而会记住之前的知识;终身学习是实现人类级别智能的必经之路;
- 实际应用:独立式学习消耗大量数据,如果能吸收在之前其他学习过程学到的知识,就再好不过了。
作者举了几个应用例子。第一个是 NLP 中的语义分析,例如分析大量用户评论中对商品的评价。互联网公司常需要大量处理这种任务,随着任务的增多,新东西其实越来越少,比如商品的属性就那么多,用户出现的评价词也那么多,所以如果能把之前见过的东西利用起来,总是比从头学习要好的。第二个例子是自动驾驶,想想就知道,车肯定是平时在路上不断地碰见新路况慢慢学起来的(又不能把之前的忘掉),而不是给它看到所有情况让它一口气学完,这种任务天生就不能独立式学习。第三个例子是聊天机器人,人类说的话是无穷无尽的,总是能碰到没见过的对话,人类的处理方式通常是结合自己学过的知识猜出新话的意思,而很多”人工智障“的机器人就傻傻不知道做什么了!(之前 B 站的梗联通客服图灵测试给大家一乐~)所以聊天机器人也必须持续学习起来!
终身学习定义
这里只能给一个概念上的、形而上的定义,因为终身学习的研究繁多,只有统一的思想,而没有统一的数学框架。下面就像《人工智能》课程讲的各种 agent 一样,一张流程图即可描述:
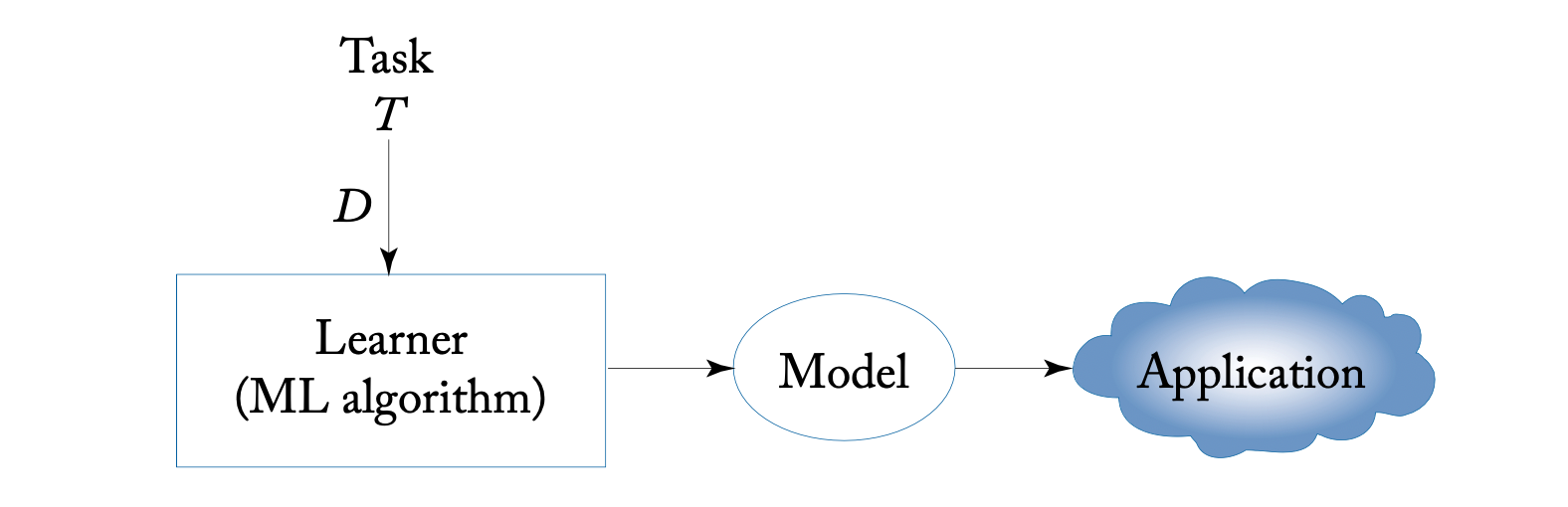
独立式学习很简单,目标就是一个任务 \(T\),用一个数据集 \(D\),用学习算法学到一个模型,再去应用(测试)。
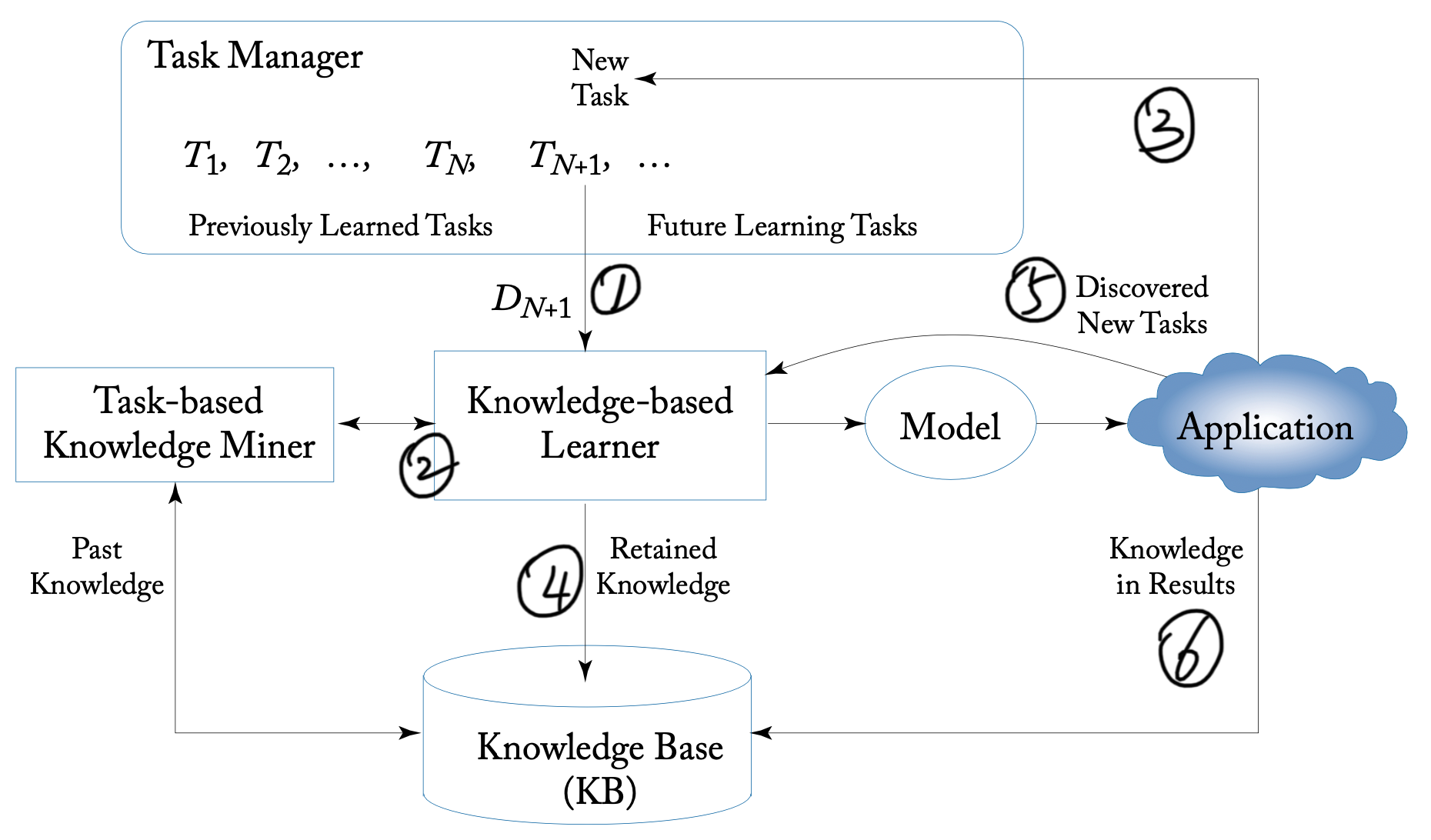
终身学习的目标是一系列任务 \(T_1, \cdots, T_N\),在处理任务 \(T_{N+1}\) 时,不仅用它的数据集 \(D_{N+1}\)(图中①),还利用了之前存下的知识(图中②)。终身学习多了一个部件用于存储过去的知识,称为 Knowledge Base(KB)。此时应当把新任务的知识存到 KB 中(图中④),为下一个任务作准备。这样学习到模型后再去应用(测试新任务,图中③),应注意这里模型只有一个在不断改进,而不是从新开始学。
除了以上最基本的终身学习流程,很多终身学习模型会涉及很多不同的细节,作者也总结到图里了:
- 有的终身学习还要求能够自动发现新任务(图中⑤),例如无人驾驶、聊天机器人都有这需求。这其实是一件很困难的事。
- 还有的在应用阶段也会发现一些新东西出来,反馈给 KB (图中⑥)。
- KB 可以理解为是静态的且复杂的数据库,里面都是生数据,有时需要检索工具去发掘自己需要的信息。这就是图中多出来的一个模块 Task-based Knowledge Miner(TKM)。
- 某些复杂的系统需要对任务调度管理,就是图中的 Task Manager(TM)。
存储了什么知识?
KB 是存储过去知识的地方,也就是体现终身学习思想的核心模块。它里面存了些什么呢?当然是模型设计者决定的,但总结起来常常是这几种:
- 直接信息(Past Information Store):即之前任务中的直接训练结果或模型的直接输入输出,例如:
- 之前任务用的数据 \(D_1,\cdots, D_T\)(持续学习中称为重演数据)
- 之前任务模型的输出(持续学习常用在蒸馏损失)
- 之前任务训练的整个或部分模型
- 比直接信息更高一层的元信息(Meta-Knowledge Store/Miner):这里说的就是元学习的思想
- 知识推理机(Knowledge Reasoner):这比前一个还厉害,不仅能把直接信息归纳成元信息,还能自我理解推断新的信息出来。我觉得这就有点像是吹牛的东西了。
作者另外提到了全局知识和局部知识的概念,和他们自身科研项目有关,感觉意义不大。
另外,本书多次强调好的知识应该是什么样子:首先应当保证过去知识是正确的、无偏置的(正确性),才能考虑此知识是否适用当前的新任务(适用性)。也是一种观点吧,但就是太笼统。
本章最后讲了一下终身学习的评估方式,写的很水,没什么干货,就不放了。