本文介绍如何自定义模型,即 nn.Module 模块的逻辑与使用方法。由此可以搭建自己的深度网络结构。本文参考 Dive into Deep Learning (PyTorch 版) 中的以下内容:
- 5.1、5.6 节:层和块,自定义层。
nn.Module 官方文档:https://pytorch.org/docs/stable/generated/torch.nn.Module.html
之前见到的所有高级 API 定义的模型全是使用 PyTorch 现有的模版:由 nn.Sequential() 包裹的 nn.Linear(), nn.Flatten(),用它们定义出的模型非常默认,不够灵活。设计更复杂的网络结构,这种默认的就无法满足需求了,需要自定义模型。
在逻辑层面上,所有网络模型都是由块(block)组成的,块与块之间可以有各种顺序、嵌套、并列等关系。块中包含一个或多个层(layer)。在 PyTorch 的语义中,模型最小单位不是神经元而是层。
通用 nn.Module 模版
在代码写法上,所有块、层都是 nn.Module 对象,包括 PyTorch 现有的 nn.Linear(),nn.Flatten() 甚至 nn.Sequential()。下面是通用的自定义 nn.Module 对象的写法。
1
2
3
4
5
6
7
class MyModule(nn.Module):
def __init__(self, ???)
super().__init__()
self.参数 = ...???
def forward(self, X):
return ... # X 的表达式
定义的规则是,只要定义好前向传播 forward 函数,里面包含的是 torch 运算,再确保把这些运算的参数(即网络参数)封装到此模型的类中即可。forward 函数是核心,在自定义 nn.Module 对象时必须要写,__init__() 函数只是一个将 forward 函数所需变量绑定于此类的容器。下面做一个小试验,体会其重要性:
1
2
3
M = nn.Module()
M()
M.forward()
这段代码第二、三行都会报 NotImplementedError,提示 forward 函数未定义。为什么会这样?nn.Module 模块的源代码解释清楚了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def _forward_unimplemented(self, *input: Any) -> None:
raise NotImplementedError(f"Module [{type(self).__name__}] is missing the required \"forward\" function")
class Module:
#...
forward: Callable[..., Any] = _forward_unimplemented
def _call_impl(self, *input, **kwargs):
forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward)
#...
result = forward_call(*input, **kwargs)
#...
return result
__call__ : Callable[..., Any] = _call_impl
#...
nn.Module 设计的机制就是要求继承时必须重写一个 forward 函数。此外,可以直接调用 nn.Module 对象,其实就是给定输入 \(x\) 前向传播一遍得到预测结果,它由 __call__() 方法定义(见 Python 笔记),而实现中可以看到出现了 self.forward,所以不写 forward 函数,在训练时前向传播也会报 forward 函数未定义的错误。
另外,在构造函数中必须调用父类 nn.Module 的构造函数:super().__init__(),为了把 nn.Module 定义的一些实例属性继承过来,只能这样写。写 nn.Module 对象时都要调用一下,否则会因缺少里面的属性报变量未定义的错误。感兴趣可以看看这些实例属性是什么:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Module:
# ...
def __init__(self) -> None:
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters: Dict[str, Optional[Parameter]] = OrderedDict()
self._buffers: Dict[str, Optional[Tensor]] = OrderedDict()
self._non_persistent_buffers_set: Set[str] = set()
self._backward_hooks: Dict[int, Callable] = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks: Dict[int, Callable] = OrderedDict()
self._forward_pre_hooks: Dict[int, Callable] = OrderedDict()
self._state_dict_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_pre_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_post_hooks: Dict[int, Callable] = OrderedDict()
self._modules: Dict[str, Optional['Module']] = OrderedDict()
#...
有了以上模版,我们可以使用 nn.Module 写一个层,也可以写一个块,乃至块组成的一整个模型,非常灵活。网络的结构取决于 __init__() 和 forward 函数怎么写。以下每种情况分别给出两段代码:一段是调用现有的模版,另一段是自己继承 nn.Module 手写出来的;这两段代码写出来的效果是一样的。
自定义层
例 1:全连接层。 现有的模版:
1
net = nn.Linear(8, 128)
等价于以下自定义的层:
1
2
3
4
5
6
7
8
9
class MyLinear(nn.Module):
def __init__(self, input_num, output_num):
super().__init__()
self.weight = nn.Parameter(torch.randn(input_num, output_num))
self.bias = nn.Parameter(torch.randn(output_num, ))
def forward(self, X):
return torch.matmul(X, self.weight.data) + self.bias.data
net = MyLinear(8, 128)
例 2:ReLU 激活函数层,它是一个不带参数的层。 现有的模版:
1
relu = nn.ReLU()
等价于以下自定义的层:
1
2
3
4
5
class ReLULayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return nn.functional.relu(X)
参数打包成 nn.Parameter 类后,直接定义为实例属性,forward 函数直接拿来用。实际使用时,一般很少自定义层,一般的网络都是使用那些常用层如全连接层、卷积层等,然后按照下面的方式组合成块。
自定义块
例:多层感知机(MLP)。现有的模版:
1
2
3
4
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
等价于以下自定义的层:
1
2
3
4
5
6
7
8
9
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(784, 256)
self.out = nn.Linear(256, 10)
def forward(self, X):
return self.out(nn.functional.relu(self.hidden(X)))
net = MLP()
也就是说,一些定义了层的 nn.Module 对象能以这种方式嵌套进定义了块的对象。
上面两者还有微小的区别:前者使用 nn.Sequential,用下标 net[0],net[1]索引各层,还能把激活函数当作层索引到;后者的层是放在实例属性上的,需要用 . 来索引。
nn.Sequential 是一种特殊的 nn.Module 对象,如上所述它能起到顺序连接各层、充当列表的效果。它的原理可以参考书中的简单复现,由此例可以体会到自定义 nn.Module 对象的灵活性:
1
2
3
4
5
6
7
8
9
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
self._modules[str(idx)] = module
def forward(self, X):
for block in self._modules.values():
X = block(X)
return X
可以看到,它可以传入任意多个 nn.Module 对象(可变参数 args),将其顺序存储在 _modules(之前见过是 nn.Module 的实例属性,这里就派上用场了,是一个 collections.OrderedDict 容器),然后在 forward 函数中顺序复合到输入 X 上。(注意,这样使得激活函数也可作为可变参数传入。)
自定义块组成的模型
nn.Module 对象是可以一层一层地递归嵌套地定义的。以下是一个稍复杂的例子:
1
2
3
4
5
6
7
8
9
10
11
class NestMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU())
self.linear = nn.Linear(32, 16)
def forward(self, X):
return self.linear(self.net(X))
chimera = nn.Sequential(NestMLP(), nn.ReLU(), nn.Linear(16, 10))
现在思考,为什么可以这样嵌套呢?因为在前向传播时,会一层一层递归地调用被嵌套模块的 forward 函数。例如此例,调用时 chimera(X) 时,首先会调用 nn.Sequential 的 forward 函数,即依次调用 X = NestMLP()(X), X = nn.ReLU()(X), X = nn.Linear(16, 10)(X),前面说过每一层都会调用各自 forward 函数,例如先调用 NestMLP() 的 forward,其中调用了 self.net(), self.linear(),它们又会调用里面的 nn.Sequential(...),nn.Linear(32, 16) 的 forward 函数。如此递归下去,直到遇到真正层里面的参数,例如 self.linear 里面的 weight。这种 forward 函数递归过程会把嵌套的每一块、层的参数都遍历到,从而能反向传播。此递归调用相当于遍历下面这颗树:

有人会问,为何不用简单的:
1
2
3
4
chimera = nn.Sequential(nn.Linear(20, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, 16), nn.ReLU(),
nn.Linear(16, 10))
这就要从方便性的角度考虑了。这种方便不只在命名上(见下)。在逻辑上前者是将网络分成了几个块,例如本例有点像 NestMLP 是特征提取器,后面的全连接层是分类器的意思,假如以后想换个特征提取器更方便。
最后讨论一下命名问题。模型的每个块、层都有自己的名字(类似变量的命名空间),且可以通过以这个名字命名的实例属性访问。在这种封装的模型类中,嵌套关系的存在使得各块、层有树形关系。例如上面的 NestMLP 模型各块、层的名字如下:
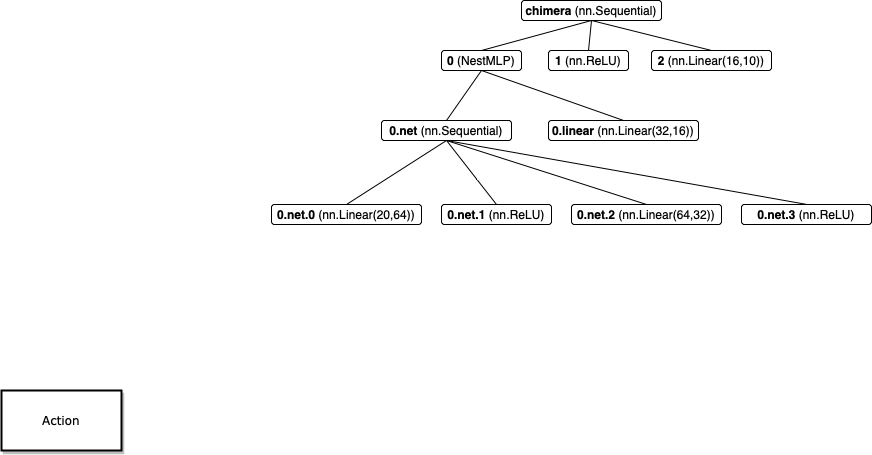
print()函数能以一种规整的方式打印出网络结构(是由类特殊方法__print__()和__repr__()定义的,见 Python 笔记),会显示各块、层的名字、网络结构。也可以使用 Tensorboard 等工具可视化,见 Tensorboard 笔记。