本文统一整理深度学习的训练细节的理论知识,算是给以后的科研实践打基础。具体的实践经验见另一篇笔记:《深度学习训练实践经验》。
本文按训练流程分几个主题,包括激活函数的选择、数据预处理、参数初始化、优化器的选择、超参数优化等等。我将在每个主题中介绍该主题的理论,介绍其中的各种方法、trick 及其优缺点,最后介绍实际项目中的实践经验。另外过拟合、欠拟合是深度学习的大问题,将单独抽出一章来讲解其理论并介绍应对过拟合的方法。
本文主要参考计算机视觉课程 Stanford CS231n以及书《动手学深度学习》的第 4 章。
目录
开始之前,先把反向传播的原理1写在这里,这是深度学习训练的核心算法。后面用到的符号与以下公式一致。
根据链式法则,反向传播是按层迭代的:损失函数对一层神经元(激活前)\(a_j^l\) 的梯度按层向后传播,传播就是不断乘以该层权重以及该层激活函数的导数:
\[\delta_{j}^{l}=\sum_{k=1}^{r^{l+1}} \delta_{k}^{l+1} w_{j k}^{l+1} g^{\prime}\left(a_{j}^{l}\right)=g^{\prime}\left(a_{j}^{l}\right) \sum_{k=1}^{r^{l+1}} w_{j k}^{l+1} \delta_{k}^{l+1} \ \ \ \ (1)\]得到对第 l 层神经元的梯度后,再乘以第 l-1 层(激活后)\(o_i^{l-1}\) 就是对权重 \(w_{ij}^{l}\) 的梯度:
\[\frac{\partial L}{\partial w_{i j}^{l}}=\delta_{j}^{l} o_{i}^{l-1}=g^{\prime}\left(a_{j}^{l}\right) o_{i}^{l-1} \sum_{k=1}^{r^{l+1}} w_{j k}^{l+1} \delta_{k}^{l+1} \ \ \ \ \ \ (2)\]一、激活函数
激活函数(activation function)是作用在每个神经元上的函数,神经元激活前的 \(a_j^l\) 受其激活为 \(o_j^l\)。激活函数不仅构成模型的一部分,而且也非常影响训练过程。不合适的激活函数会大幅降低训练效率,甚至“毙掉”训练过程。常用的激活函数有 Sigmoid、Tanh、ReLU 等,下面将探讨它们对训练过程的影响。
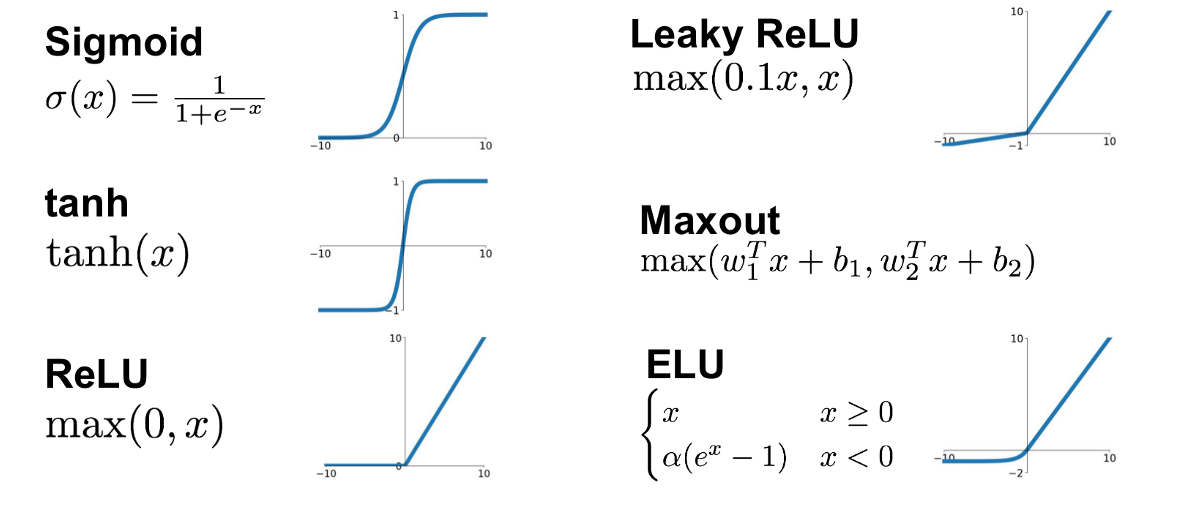
Sigmoid, Tanh
Sigmoid 函数是最早使用的、也是用在第一批神经网络的激活函数。
优点:
- 值域为 \([0,1]\),可以解释为概率;
- 原理类似于真实神经元的激活,有很好的生物学解释。
缺点:
- 很容易产生梯度消失现象(又称饱和现象,下文解释),导致靠输入端层的梯度很小,参数不更新;
- 值域不以零为中心,可能导致 zig-zag 现象出现,降低参数更新效率;
- 指数函数计算代价高。
梯度消失现象:随着反向传播,梯度与很小的数值累乘最后无限接近 0,使梯度下降参数更新非常缓慢。
反向传播时,中间某层某神经元激活函数的导数 \(g^{\prime}\left(a_{j}^{l}\right)\) 特别小,就会导致之后在其基础上累乘的梯度也特别小,即产生梯度消失现象。根据公式 (1),反向传播计算梯度是累积的,网络越深,越靠近输入端权重的梯度消失得越厉害。
Sigmoid 很容易梯度消失,因为它的导数很容易小,见其导数图像:只要某层某神经元的输入 \(a_j^l\) 离 0 很远,导数就很小(称为饱和);即使在 0 附近,导数值也只有 0.25 左右,仍然会随着累乘让梯度逐渐消失。
对零中心问题的解释:
设第 l-1 层选用 Sigmoid 激活函数,由于其值域恒正,无论之前层如何,该层所有神经元的输出 \(o_i^{l-1} (i = 1,2,\cdots)\) 都为正。考虑其后连接的权重的梯度,根据反向传播公式 (2),考虑 l-1 层所有神经元连接到第 l 层某一个神经元的权重(即 \(w_{ij}^l\) 固定 \(j\),考虑所有 \(i\)),由上层传到第 l 层这个神经元的信号 \(\delta_j^l\) 都相同,且 \(o_i^{l-1}\) 同号,则这些权重的梯度也同号。
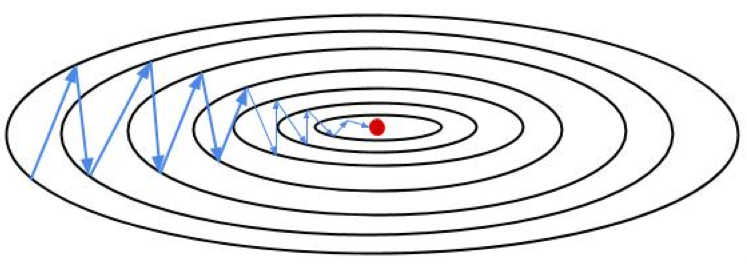
下图将这些权重画在二维空间中示意。由于梯度同号,权重更新时要么向右上、要么向左下(视 \(\delta_j^l\) 符号而定),要是最优解实际在起点的右下方时(高维空间更可能发生),就会发生图中所谓 zig-zag(锯齿)现象。
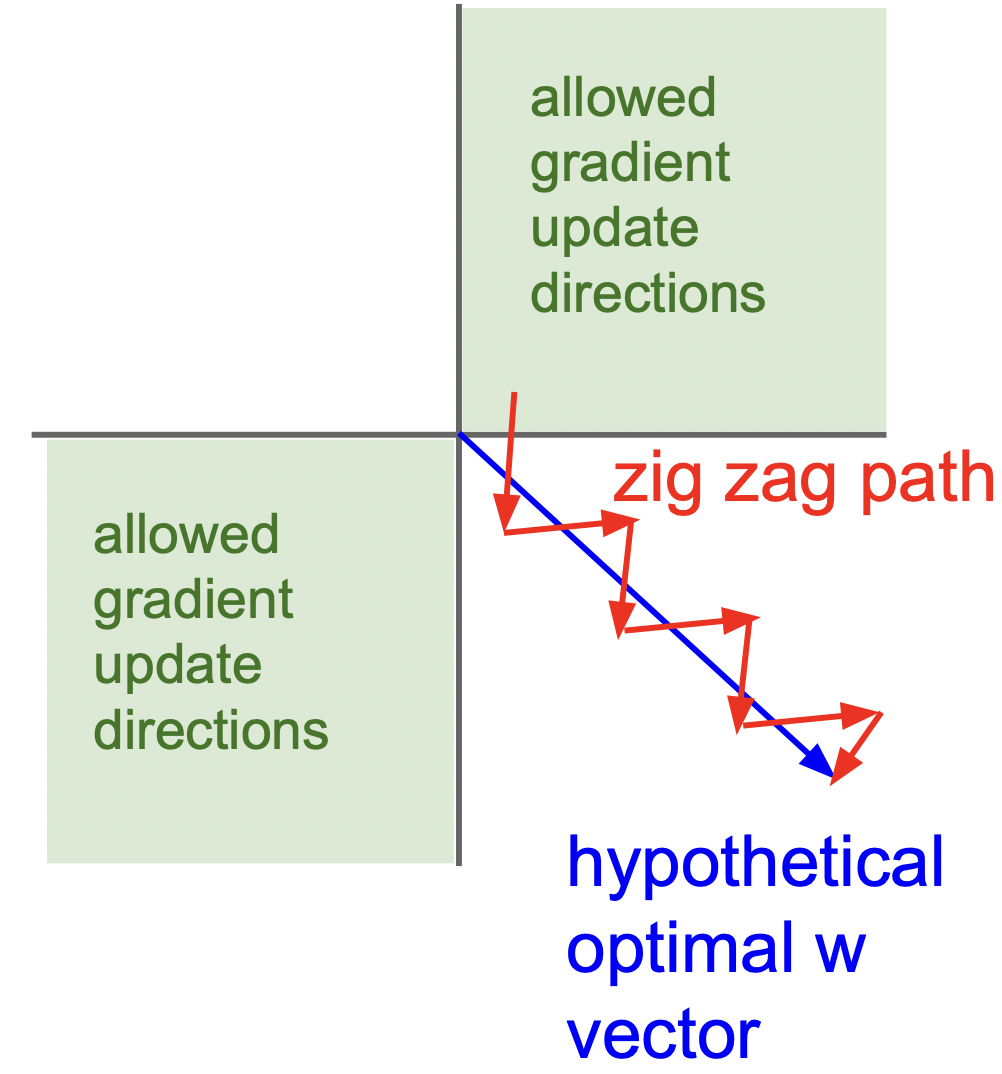
纵观整个网络,哪一层用 Sigmoid 激活,哪一层后面的权重就像被划为几个大组(\(w_{ij}^l\) 每个 \(j\) 遍历 \(i\) 是一组),组内梯度永远同号。这样事实上限制了参数更新的自由。
值域恒正的激活函数比较极端,会导致组内梯度永远同号。更一般的情况中,激活函数值域大于 0 占的情况多一点,导致同号现象不是必然出现,但概率也大,也会降低参数更新效率。就这一点,最理想的激活函数应该是值域以零为中心(zero-centered),让 \(o_i^{l-1}\) 正负号出现的机会均等。
Tanh 函数就是把 Sigmoid 函数拉伸并平移到原点中心。它是对 Sigmoid 函数的改进,主要解决零中心问题。
优点:值域以零为中心。
缺点:
- 梯队消失现象;
- 指数函数计算代价高。
ReLU 及其变种
ReLU 函数(Rectified Linear Unit,整流线性单元)第一次出现在 2012 年 AlexNet 中,随后被大量使用。
仔细观察 ReLU 及其导数,可以看到其逻辑很简单,可以描述为只有两种状态:激活与未激活,以函数输入 \(a_j^l\) 的正负作为唯一判断。对一个 ReLU 神经元:
- \(a_j^l\) 为正意味着被激活,前向传播的输入值、反向传播的梯度都原封不动地放行;
- \(a_j^l\) 为负则意味着未激活,前向传播、反向传播到此全被堵住,无论输入值还是回传的梯度全都变 0。
(注:前向传播考虑 \(g(a_j^l)\),前者为 a_j^l,后者为 0;反向传播考虑 \(g'(a_j^l)\),前者为 1,后者为 0)
优点:
- 在大于 0 部分不会出现梯度消失现象;
- 函数很简单,计算效率非常高。
缺点:
- 在小于 0 部分梯度不仅是消失,而是直接变为 0,有网络部分权重永不更新的危险,即有一些 ReLU “挂掉”;
- 值域不以零为中心。
对 ReLU “挂掉” 的解释:
上面看到只要喂给 ReLU 的输入是负的,上一层连接到此神经元的那些权重就都不更新此步了。在一个大网络里这种事会经常发生,是会影响效率的。
除此之外有时还有 “挂掉” 的危险。一个 ReLU 神经元 \(RELU(a_j^l)\) “挂掉” 是指它永不被激活,导致连接的权重 \(w_{ij}^l (i=1,2,\cdots)\) 永不更新,出现网络的一部分还没训好就结束训练的现象。
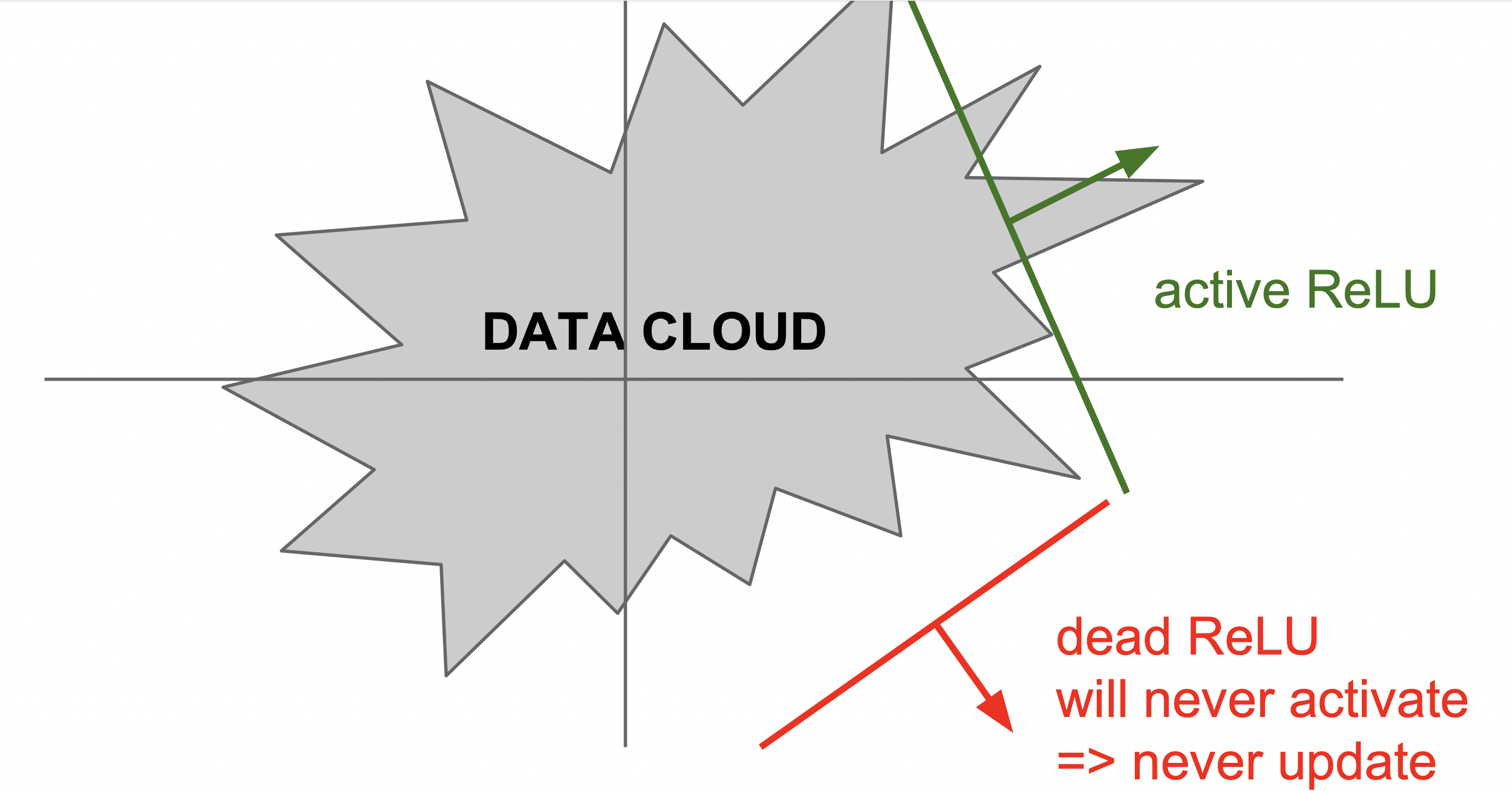
什么时候会 “挂掉” 呢?以此示意图解释,设上层 l-1 层输出值 \((o_1^{l-1}, o_2^{l-1},\cdots)\) 是二维空间的点,所有训练数据对应的点构成一片 data cloud。一个训练数据 l-1 层输出值 \(o^{l-1}\) 经过权重的线性组合得到 \(a_j^l\),要看它大于还是小于 0,就是看它在 cloud 中对应点落在直线的哪边(直线位置是权重决定的)。如果不巧直线正好落在 cloud 外,这样无论拿什么训练数据训练就都无法更新了,即 “挂掉” 永不更新。在参数更新的过程中,难免会不小心训练出这种不巧的权重(例如优化器不太稳定时,如学习率太高),而一旦发生这个意外,后果还是很严重的。
当然,上面假设了 data cloud 不变化,由于图示空间实际是它的表示而不是原始输入,前面的权重也会更新,所以 data cloud 是变化的,有可能在以后 data cloud 会跨过直线,将其盘活。但事实上还是有 “挂掉” 现象的存在,不妨碍我们上面简单地理解。理论分析有论文可参考:Dying ReLU and Initialization: Theory and Numerical Examples
Leaky ReLU、参数化 ReLU、ELU 等都是 ReLU 大规模应用随后提出的对 ReLU 的改进。
优缺点:Leaky ReLU 解决了 ReLU “挂掉” 的问题;参数化 ReLU 就是把 Leaky ReLU 的负斜率变成了可学习的参数,更加灵活;ELU 试图融合 ReLU 和 Leaky ReLU,也解决了 “挂掉” 的问题,但引入的指数函数让计算代价变高。
对它们的优缺点还有很多争议。激活函数是深度学习的一个领域,感兴趣可以阅读相关论文。
Maxout
Maxout 是 Goodfellow 于 ICML 2013 提出的一种激活函数。它最大的特点是输入不是一个,而是多个,它的输出是取多个输入的最大值。实际上它是单输入 ReLU 函数的推广,因为 ReLU 就是将输入和常值 0 比较大小。
在结构关系上,它也是对神经元的作用,即称呼 “Maxout 神经元”。Maxout 神经元形式上可以看成与普通的神经元一样——尾部连接若干个前一层的神经元。但实质上这些权重是 2 份互相独立的,只是共用了两端连接的神经元。
优缺点:继承了 ReLU 的所有优点,缺点是参数量加大了多倍。
二、数据预处理
这里的数据预处理是指能作用于训练过程的统一范式,而不是实际项目中对真实数据的具体处理流程。对训练过程有作用的预处理方法主要是以下几种。
数据标准化
数据标准化(normalization),最常见的做法是将数据的每一维减掉该维的均值,并除以标准差。前者称为零中心化,后者称为归一化。
零中心化作用:
- 非零中心化的数据对模型权重的改变更加敏感,导致难以优化,见下图;
- 当激活函数值域零中心化后,对数据零中心化也可以减少 zig-zag 现象;
- 让 data cloud 集中于原点附近,在上面 ReLU “挂掉” 的问题中,如果配合初始化 bias 参数为 0,可以在训练之初就避免直线不穿过 cloud,防止 “挂掉”;
- 最主要原因还是只有零中心化后才可以谈归一化,不减掉均值就除以标准差是没有意义的。
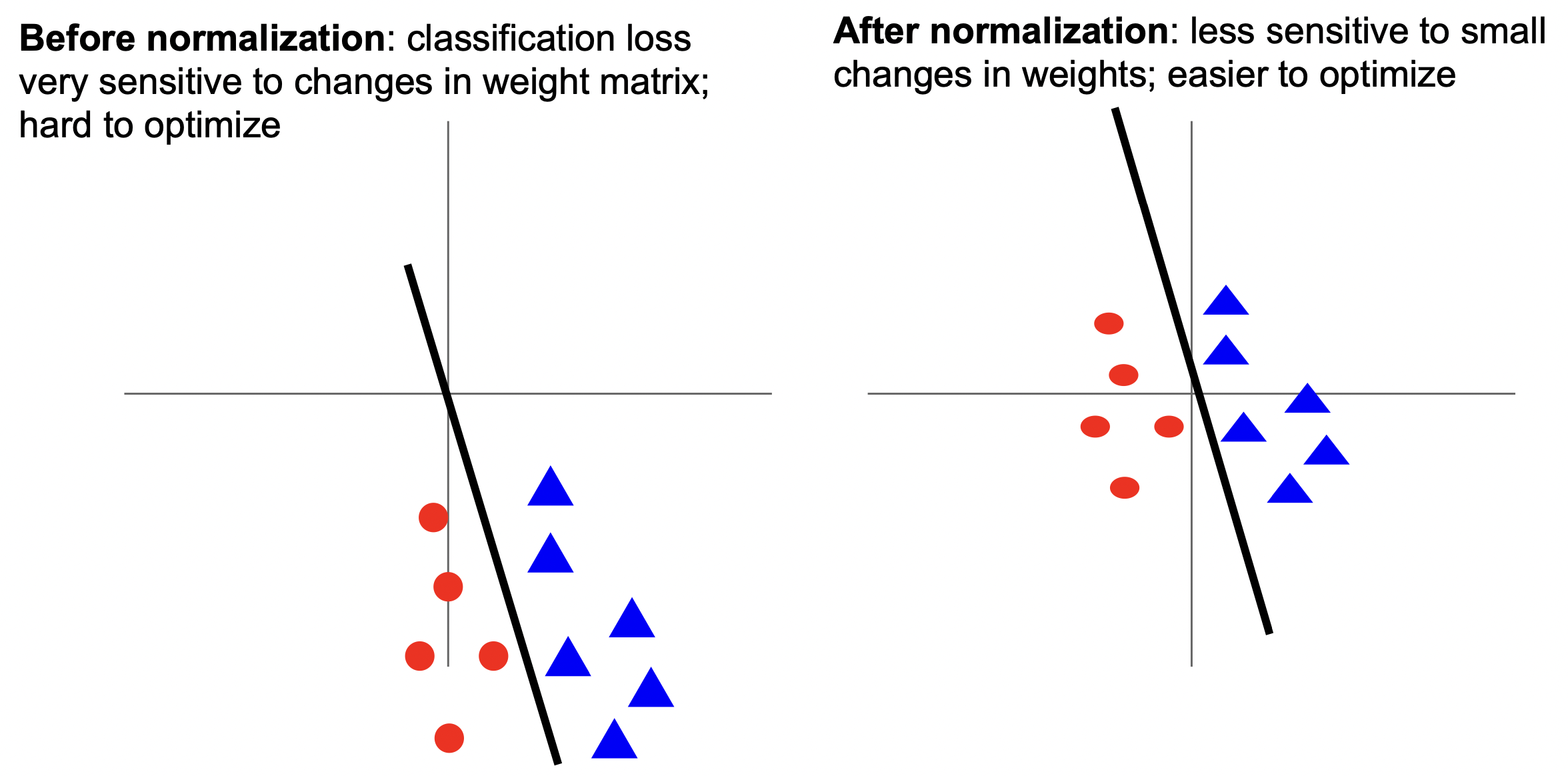
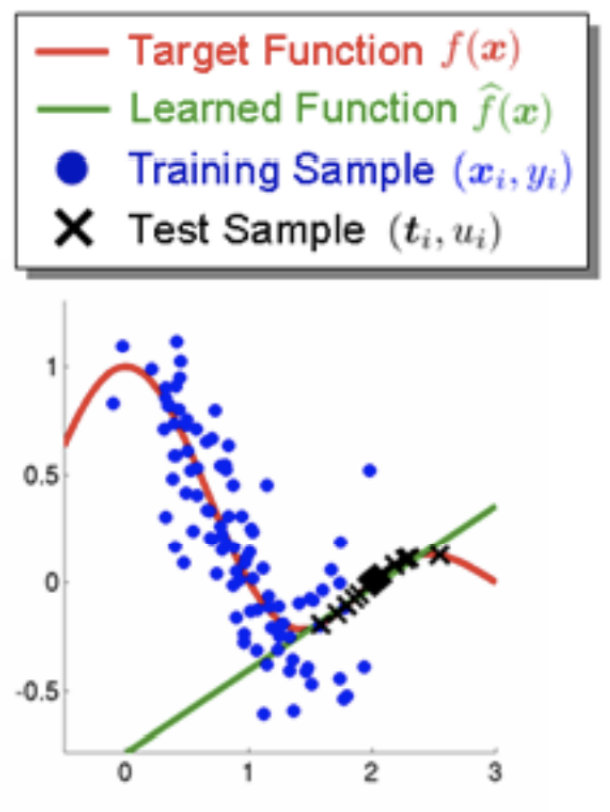
归一化作用:让数据的各个特征的值域范围统一起来,使损失函数更加倾向于圆润而不是狭长,有利于优化。狭长的损失函数也容易导致 zig-zag 现象,见下图,在学习率稍大时极容易 overshot。
数据标准化对训练集和测试集都要做,且所用的均值和标准差必须是一样的,统一用训练集的(因为训练时没有测试数据,而测试时有训练数据)。
还有很多其他类似标准化的处理手段:
- min-max 标准化:每一维减掉该维的最小值,并除以极差,可以把数据缩放到 \([0,1]\) 区间。极容易受个别数据影响,不常用;
- 比例归一化:每一维除以该维的和,也可以把数据缩放到 \([0,1]\) 区间,不常用。
降维
有一些手段可以起到降维的作用:
- 主成分分析(PCA):相当于把原数据做了线性变换,使其第一维是最主要成分(方差最大),第二维是次主要成分,以此类推。它提前抓取了(线性意义下的)主要特征,某种程度上方便以后的训练。如果愿意的话,可以选取前 \(k\) 个主成分,即可降维;
- PCA 白化(whitening)在 PCA 基础上减掉均值除以标准差。
- ZCA 白化 在 PCA 白化基础上作 PCA 的逆线性变换。
- 线性判别分析(LDA):相当于把原数据作了线性映射(比原来维数低),使数据在新空间上分得尽量开。
数据增强
数据增强(data augmentation)是将现有训练数据衍生出各种变换的数据,将其加入训练。它起到增大数据量的作用,因此是减轻过拟合的手段。
以图像数据为例,常用的变换有水平/垂直翻转、裁剪缩放、色彩抖动等等甚至很多高级的变换(参考数字图像处理知识)。
当然数据增强并不只是简单地寻找各种变换,还发展出了各种学习范式,以下是一个例子,使用在 ResNet 原论文中:
- 训练阶段:随机以统一尺寸裁剪训练图像,使用裁剪的片段训练;
- 测试阶段:裁剪测试图像的几个固定位置(例如四个角+中间),输入模型得到结果,再投票或平均。
分布偏移校正
机器学习假设训练数据和测试数据同分布,即都是从一个联合分布中取出来的:\(p_s(\mathbf{x}, y)\)。但实际数据可能并不满足这一条件,称为分布偏移,这种情况下测试效果肯定不好。
分布偏移有以下几种类型,下面是统计学上的理解:
- 协变量偏移(covariate shift):\(p_s(\mathbf{x}, y) = p(\mathbf{x}) p(y \mid \mathbf{x})\),协变量 \(\mathbf{x}\) 的分布 \(p(\mathbf{x})\) 不同,而标签与协变量的关系 \(p(y \mid \mathbf{x})\) 相同;
- 标签偏移(label shift):\(p_s(\mathbf{x}, y) = p(y) p(\mathbf{x} \mid y)\),标签 \(y\) 的分布 \(p(y)\) 不同,而标签与协变量的关系 \(p(\mathbf{x} \mid y)\) 相同;
- 概念偏移(concept shift):而标签与协变量的关系 \(p(y \mid \mathbf{x})\) 不同。
协变量偏移和标签偏移其实是同一个问题的两种形式,比较常见,例如下面两幅图的情况;概念偏移是最严重的偏移,意味着训练数据和测试数据蕴含的知识不是一码事,例如二分类问题,训练集 1 代表猫、0 代表狗,到了测试集 1 代表黑物体、0 代表白物体,此时标签 1,0 的含义都不一样了,在分类猫狗上训练的模型完全不适用分类黑白物体。

有时候分布偏移并无大碍,尤其是非概念偏移,模型还是能正常工作。当模型想尽办法怎么调也效果不好时,就要考虑数据是否偏移过大,并解决分布偏移了。
识别是否有分布偏移必须比较训练数据和测试数据,通常是通过统计、观察来判断,至于分布偏移属于哪种类型,根据数据是判断不出来的,只能通过对当前问题的理解、经验来判断。
解决分布偏移的方法:如果判断是概念偏移,那没救了,出了从零开始收集新数据别无妙方;如果不是概念偏移,即协变量偏移和标签偏移,《动手学深度学习》书中提供了两种偏移纠正算法:协变量偏移纠正、标签偏移纠正。
协变量偏移纠正算法:
- 构造一个二分类数据集:\({(\mathbf{x}_1, -1), \cdots, (\mathbf{x}_n,-1), (\mathbf{u}_1, 1),\cdots, (\mathbf{u}_m, 1)}\),其中 \(\mathbf{x}_i,\mathbf{u}_j\) 分别来自训练集、测试集;
- 训练 Logistic 回归模型 h;
- 在真实训练时,损失函数对数据加权:\(min \frac1n \sum_{i=1}^n \beta_i l(f(\mathbf{x}_i), y_i)\),权重值 \(\beta_i = \exp(h(\mathbf{x}_i))\) 或 \(\min(\exp(h\mathbf{x}_i), c)\)(\(c\) 为常数)
标签偏移纠正算法是对 \(y_i\) 做处理,不再介绍。
注意纠正算法应用在正式训练之前,要用到测试数据的部分信息,可能是一种不被允许的作弊,应慎用。
三、网络结构
本章介绍对网络结构下手的通用的训练 trick。
Dropout
Dropout 是 Google 于 2014 年提出的 一种层。它将上一层输出 \(o_1^{l-1}, o_2^{l-1}, \cdots\) 以设定好的概率 \(p\) 随机置为 0,得到它的输出 \(o_1^t, o_2^t, \cdots\)。
注意:
- 是将一层的激活值 \(o\) 置 0,而不是激活前的 \(a\)。后者的效果是与被置 0 的 \(a\) 相连的权重梯度为 0,完全不更新;而 Dropout 并不是这样的,可理解为它将某些参数的完全不更新现象平均到所有参数了;
- 丢弃概率 \(p\) 是超参数而不是可学习的参数,因此 Dropout 是一个不带参数的层。
类似 Dropout 的有 DropConnect,置 0 的不是输出而是一层的权重。它不是单独的层,而是依附于别的层,应称呼 “xx层加了 DropConnect”。它和 Dropout 起的作用类似。
在测试阶段,模型必须固定,这种随机的 Dropout 层就要固定下来。简单的做法是不管 Dropout 层,直接原封不动地通过,但这使得测试与训练的模型不一致。折中方案是在测试阶段对 \(o_i^{l-1}\) 乘以丢弃概率 \(p\),它等价于在训练阶段乘以 \(p\)。应选择后者,要尽量将计算量放到训练时。
Dropout 起到的作用:
- 缓解过拟合:迫使前向传播时不时丢弃一些特征,减少模型对使用所有特征的依赖,更容易学到泛化的知识;
- 打破对称性陷阱:见 “四、参数初始化” 章节。
缺点:会降低训练速度,因为 Dropout 可理解为将某些参数的完全不更新现象平均到了所有参数。
Batch Normalization
Batch Normalization 是 2015 年论文 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 提出的。它不是数据预处理手段,而是一种带参数的层。
在训练过程中,当一个 batch 的数据前向传播到 BN 层,设上一层输出为 \(\mathbf{x}_1,\cdots,\mathbf{x}_m\)(m 不是维度而是 batch_size),则每个数据都作标准化
\[\mathbf{\hat{x}}_i = \frac{\mathbf{x}_i - \mathbf{\mu}_{batch}}{\mathbf{\sigma}_{batch}}\]注意是按元素的,其中均值、方差都是对于这个 batch 的,所以叫 Batch Normalization。
为了增加一些表达能力,还在其后增加了还原操作:
\[\mathbf{o}_i = \gamma \mathbf{\hat{x}}_i + \beta\]\(\gamma, \beta\) 即 BN 层可学习的两个参数。
BN 层实际上是不稳定的、有随机性的,它不是传统意义上的层,更应该看成是一种训练的 trick,因为它严重依赖训练过程,与训练 batch 的划分方式和 batch_size 都有关。
在测试阶段,模型必须固定,不稳定的 BN 层就要固定下来。标准化操作是必须固定不变,且应与训练时的基本统一。这里一种方案是,均值方差计算整个训练集的;若对整个训练集计算代价过大,另一种方案是采用整个训练集均值方差的估计。
Batch Normalization 起到的作用:
- 增加模型训练的鲁棒性,对初始化、学习率更加不敏感,更易于训练;
- 某种程度上可缓解过拟合,因为作了标准化后相当于去除了数据的一部分数据特有的信息;另外 BN 层的随机性也给模型增加了一些扰动,使其泛化能力更强。
BN 层只有在 batch_size 较大时才能发挥更好的作用,因为 batch 的均值方差更加具有代表性。举例极端情况,如果 batch_size 设为 1,BN 每次都会将这个唯一的训练数据置为常数 \(\beta\),直接导致无法训练。
集成学习
集成学习(model ensemble)是对同一个任务训练多个模型,将其结果融合。较复杂的集成学习的方法有很多,如 AdaBoost,Bagging 等等,这是机器学习课程应学的知识,也是一大研究领域,不再讲述。
简单的集成学习方法就是同时训练多个模型,结果(分类问题)投票,或取平均,或(分类问题)对计算的排名取平均。
集成学习的作用是提高模型的泛化能力,缓解过拟合,但也会带来模型规模的增大和计算代价。
四、参数初始化
参数初始化(initialization)对训练过程非常重要,涉及到从哪里启动训练的问题,稍有不慎会让整个训练过程朝向不好的方向发展。参数初始化也是深度学习研究中的专门的领域,有成百上千种初始化方法被提出。
以下讨论的参数初始化一般是针对权重的,很少有讨论 bias 的初始化规则的,通常置为 0 即可。
简单的初始化
以下是几种简单的初始化方式:
- 全部初始化为零;
- 随机初始化:所有参数从某分布中随机取样,通常为正态分布、均匀分布等。
很多时候这种未经仔细设计的初始化方式会导致数值稳定性问题,主要是梯度消失和梯度爆炸:
- 初始化一开始就是 0 或非常接近 0,容易梯度消失,因为反向传播公式 (1) 计算梯度需要与权重值累乘;
- 初始化如果过大,容易梯度爆炸(指随训练过程计算的梯度无限增大),原因同上。
上述问题前者导致参数不更新或更新很慢,后者使参数更新非常剧烈不稳定(即数值不稳定)。
此外,对一个对称的网络的权重对称地初始化(例如全部初始化为同一个值)易导致对称性陷阱,此时如果反向传播过程也是对称的(例如普通的 SGD 算法),最后训练出来地东西也是对称的,这样就和训练了一个简单得多的网络没区别了,影响网络的表达能力。只要打破一个地方的对称——初始化、优化算法、网络结构,最后训出来的东西也就不对称了。
以上两种初始化方式,全零初始化是最蠢的,它不仅导致梯度消失,也容易触发对称性陷阱,是必须弃用的初始化方式。随机初始化应当注意分布范围,避免数值过大或过小,例如正态初始化应适当选取均值与标准差。
Xavier 初始化
Xavier 初始化方法来源于 Xavier Glorot 和 Bengio 2010 年的论文 Understanding the difficulty of training deep feedforward neural networks。它的核心思想认为随机初始化不应对所有参数选用完全相同的分布,应当在层间有差异,具体来说与该层参数数目有关,理论分析见论文。
Xavier 初始化给出了随机初始化应采用的分布参数。对第 l 层参数 \(w_{ij}^l\),\(n_{in}, n_{out}\) 即 i,j 的个数:
- 正态分布应选 \(N(0, \frac{2}{n_{in}+n_{out}})\);
- 均匀分布应选 \(U(-\sqrt{\frac{6}{n_{in}+n_{out}}}, \sqrt{\frac{6}{n_{in}+n_{out}}})\)。
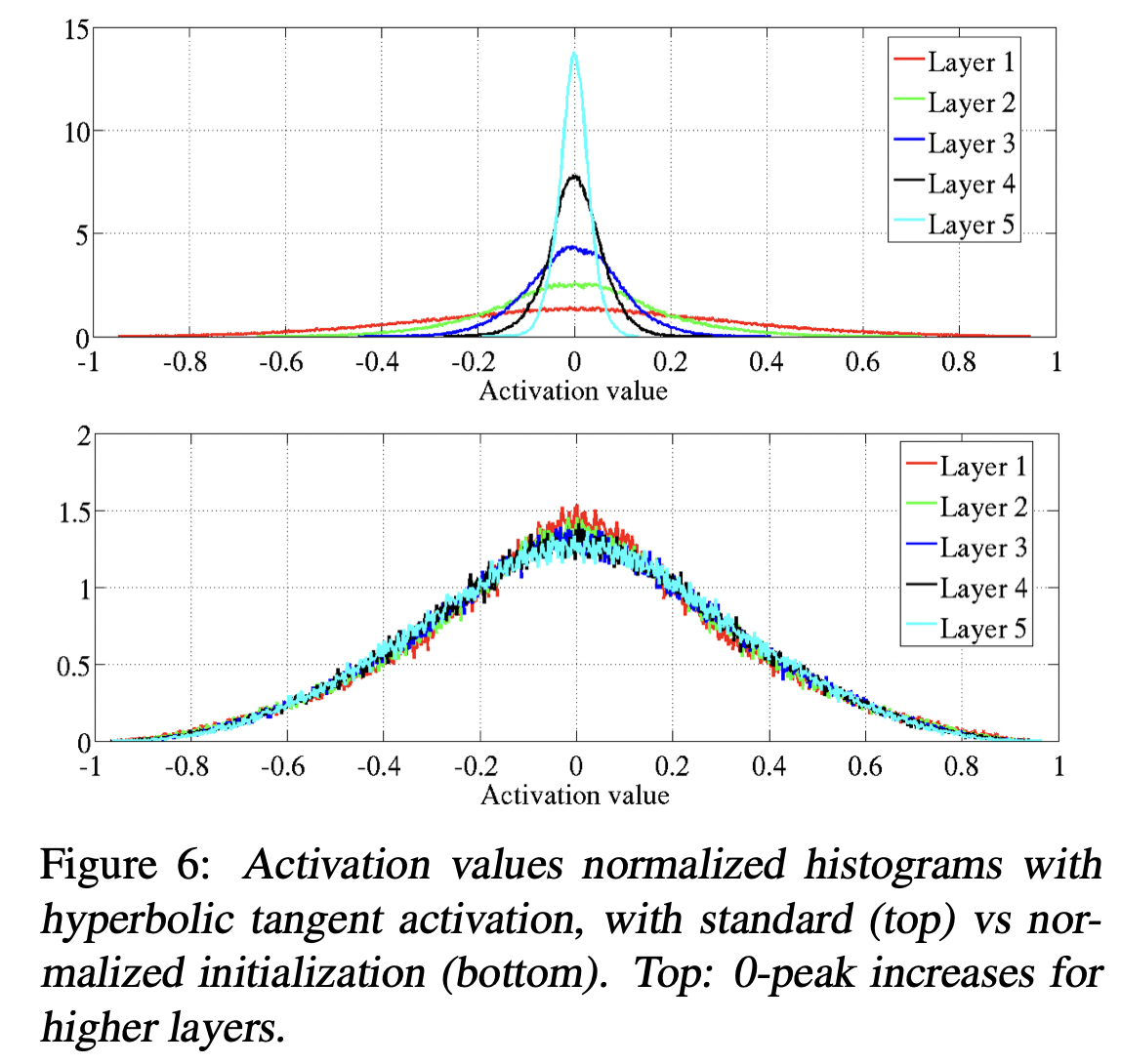
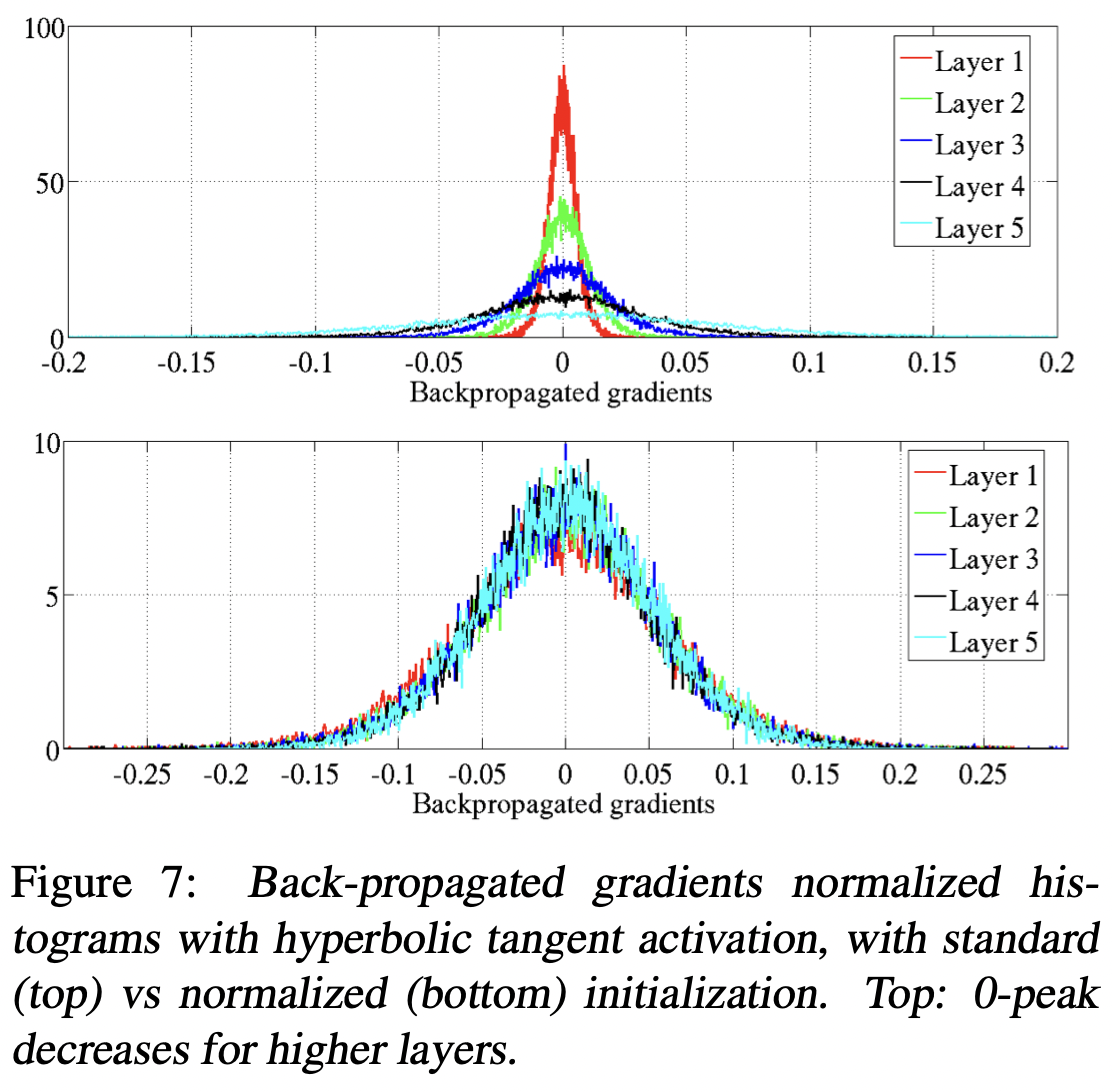
如上图,根据原论文的实验,各层全一样的正态初始化会导致随着前向传播(l 增大方向)神经元输出值 \(o_j^l\) 方差逐层递减、反向传播(l 减小)第 l 层参数 \(w_{ij}^l\) 的梯度的方差逐层递减,从而导致各参数更新的同质化。而 Xavier 初始化做的修正可以去除这种趋同的趋势。
Kaiming 初始化
何恺明于 2015 年论文 Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification 提出 Kaiming 初始化。上述几种初始化方式适用于激活函数为 Sigmoid、Tanh 等函数的基础上的,Kaiming 初始化对 ReLU 函数的情况作了额外的修正,因为它有一半被砍为 0:对选用激活函数为 ReLU 的层 l,参数 \(w_{ij}^l\):
- 正态分布应选 \(N(0, \frac{1}{n_{in}})\) 或 \(N(0, \frac{1}{n_{out}})\);
- 均匀分布应选 \(U(-\sqrt{\frac{3}{n_{in}}},\sqrt{\frac{3}{n_{in}}})\) 或 \(U(-\sqrt{\frac{3}{n_{out}}},\sqrt{\frac{3}{n_{out}}})\)。
迁移学习(预训练 + 微调)
当模型较大而数据较少时,可以直接从其他人在别的任务上训练(称为预训练)好的参数开始训练(称为微调,fine-tuning),将别的任务的知识迁移到自己的任务,这种训练策略可称为迁移学习。
名词解释:预训练使用的任务称为预训练任务,迁移过来的那个大型网络称为预训练模型;自己的任务是训练的目标,又称为下游任务。例如在 BERT 原论文中,预训练模型指 BERT 头本身,预训练任务是 MLM、NSP,下游任务就是作者跑的各种现实的 NLP 任务。
我们只要做好参数初始化,训练过程就能自动将知识迁移过来。通常的做法是将网络分为 2 部分:一部分参数有被预训练过,将其初始化为预训练的权重;另一部分参数则正常地初始化,如随机初始化。前者一般是上层网络;后者是下层,可看成分类器、输出头。显然,留给预训练的参数越少,迁移能力越强,但计算量和要求的数据量也随之增加。
在预训练 + 微调模式下,由于微调任务前的预训练阶段通常使用了大型数据,大大提高了模型的泛化能力,会缓解微调任务的过拟合。
五、优化器
深度学习的优化器有很多,参见综述论文 An overview of gradient descent optimization algorithms。本章介绍最基本的梯度下降法,以及其上的改进:Momentum,AdaGrad,RMSProp,Adam 等。
随机梯度下降(SGD)
最简单的优化算法是梯度下降(gradient descent),前面加随机二字是指损失函数并不是对所有训练数据求和,而是对采样出的一个 batch 求和,有点像用样本去估计,有一定的“随机性”。一次使用所有训练数据求和的称为 full-batch 梯度下降。参数更新公式为(以下 \(w\) 表示任意一个参数)
\[w_{t+1} = w_t - \eta \nabla l(w_t)\]此算法有一个超参数:学习率(learning rate)\(\eta\),从总体上控制参数更新的步长幅度。
缺点:
- 使得参数更新路线直来直去、呈现出突变的折线,例如当损失函数不够圆润时,容易发生 zig-zag 现象(见“数据标准化”一节第 2 幅图),降低更新效率;
- 容易陷入局部最小点或鞍点,因为在这些点附近梯度接近 0,更新步伐缓慢。深度学习维度高,在损失函数中更容易看到这种点;
- 随机性的坏处:batch 的数据可能不具有代表性,batch 损失函数可能不是真实损失的好的估计,导致更新的步伐比较混乱、随机,没有目的性。
学习率调整
学习率调整指在训练过程中不断地改变学习率,而不是一直保持不变。通常认为学习率应随着训练过程逐渐放缓,即学习率衰减。调整方式例如:
- 等间隔衰减:\(\eta = \eta_0 - kt\);
- 指数衰减:\(\eta = \eta_0 e^{-kt}\);
- 分数衰减 \(\eta = \eta_0 /(1+kt)\);
- 基于验证集指标:当验证集 loss 下降不显著时,采用某种方式降低学习率;
- ……
SGD + Momentum
Momentum 的想法是让参数的更新运动具有惯性,从物理上理解即拥有了动量(momentum)属性。参数更新公式为
\(w_{t+1} = w_t - \eta v_t\) \(v_{t+1} = \rho v_t + \nabla l(w_t)\) \(\mathbf{v_0} = 0\)
消去中间变量可得下式,可以看到参考的梯度不只是当前位置的,还会参考上次、上上次、……一直到第一次位置的,之前梯度的影响力 \(\rho^t\) 随时间指数衰减。
\[w_{t+1} = w_t - \eta (\nabla l(w_t) + \rho \nabla l(w_{t-1}) + \rho^2 \nabla l(w_{t-2}) + \cdots + \rho^{t} \nabla l(w_0)\]此算法的超参数:学习率 \(\eta\),衰减速率 \(\rho \in [0,1]\),\(\rho=0\) 时就是 SGD。
优点:
- 使参数更新路线更平滑;
- 解决了 SGD 容易卡在局部最小点和鞍点的问题,当参数更新路过这些点时,惯性更容易推着它越过这种点,而不是立刻被这些点吸引住。
缺点:
- 惯性使得参数更新容易越过(overshot)最优值,多兜圈子(想象卫星降落星球,不是垂直下落,而是反复绕圈接近)。下面的 Nesterov Momentum 缓解了这个问题。
Nesterov Momentum 对 Momentum 作了如下修正,它参考不是在参数当前位置 \(w_t\) 的梯度,而是每次越过一点到达一个预判位置 \(w_t + \rho v_t\) 的梯度。
\(v_{t+1} = \rho v_t + \nabla l(w_t + \rho v_t)\) \(w_{t+1} = w_t - \eta v_t, v_0 = 0\)
AdaGrad, RMSProp
AdaGrad(Adaptive Gradient)是 Jon Duchi 于 2010 年提出的一种学习率衰减的方法,它的特点是自适应,学习率衰减不只由时间(迭代次数)决定:
\(w_{t+1} = w_t - \frac{\eta}{\sqrt{G_t}+\epsilon} \nabla l(w_t)\) \(G_{t+1} = G_{t} + (\nabla l(w_{t+1}))^2, G_0 = 0\)
\(\epsilon\) 是一个很小的常数,防止除以 0。
可以看到其调节机制是:一个累计变量 \(G\) 不断累加梯度值的平方,随着训练过程的进行逐渐增大,而它在学习率分母下(注意这里把 \(\frac{\eta}{\sqrt{G_t}+\epsilon}\) 理解为学习率),意味着学习率越来越小,训练速度放缓。且梯度越大,累加到 \(G\) 越快,训练速度放缓地越快。
优点:
- 自适应的学习率可以让参数在快要接近最优解时自动放缓更新速度,进入更精细地搜索,防止越过最优解。因为接近最优解之前往往有较大的梯度值让参数冲向最优解,\(G\) 会累加很多;
缺点:
- 自动放缓的自适应机制是双刃剑,一旦更新到局部最小值和鞍点,就很容易陷进去,且比 SGD 更难从中拔出。
RMSProp 是对 AdaGrad 的推广,为 \(G\) 的累加引入了指数衰减机制。
\(w_{t+1} = w_t - \frac{\eta}{\sqrt{G_t}+\epsilon} \nabla l(w_t)\) \(G_{t+1} = d G_{t} + (\nabla l(w_{t+1}))^2, G_0 = 0\)
此算法的有一个超参数:衰减速率为 \(d \in [0,1]\),\(d=0\) 时为 SGD,\(d=1\)时为 AdaGrad。
优点:
- 当陷入局部最小值和鞍点时,经过足够长的时间\(G\) 会逐渐下降,学习率重新变大,更容易拔出。
缺点:
- 衰减机制也会导致 \(G\) 的累加被拖慢,一直不上去,减慢学习速度。
Adam
以上两类优化算法是对 SGD 的改进:Momentum 系列方法可看作改进了梯度,RMSProp 系列可看作改进了学习率,这两个改进互不冲突,Adam 提出于 ICLR 2015,结合了以上二者,并作了一些其他的修正:
\(w_{t+1} = w_t - \frac{\eta}{\sqrt{\tilde{G}_t}+\epsilon} \tilde{v}_t\) \(v_{t+1} = \rho v_t + (1-\rho) \nabla l(w_t), v_0 = 0\) \(G_{t+1} = d G_{t} + (1-d)(\nabla l(w_{t+1}))^2, G_0 = 0\) \(\tilde{v}_{t+1} = \frac{v_{t+1}}{1 - \rho^t}, \tilde{G}_{t+1} = \frac{G_{t+1}}{1 - d^t}\)
原 Momentum 中间变量 \(v\) 称为第一动量,RMSProp 部分累加的 \(G\) 称为第二动量。做的修正见最后一行公式,能防止一开始学习率过大导致的不稳定,原理详见论文。另外一个小区别是 \(v,G\) 的累加公式多了 \(1-\rho, 1-d\) 的系数,本质上区别不大。
Adam 合并了 Momentum 和 RMSProp 系列良好的性质。下图是各优化器效果对比图,来自 CS231n 课程:
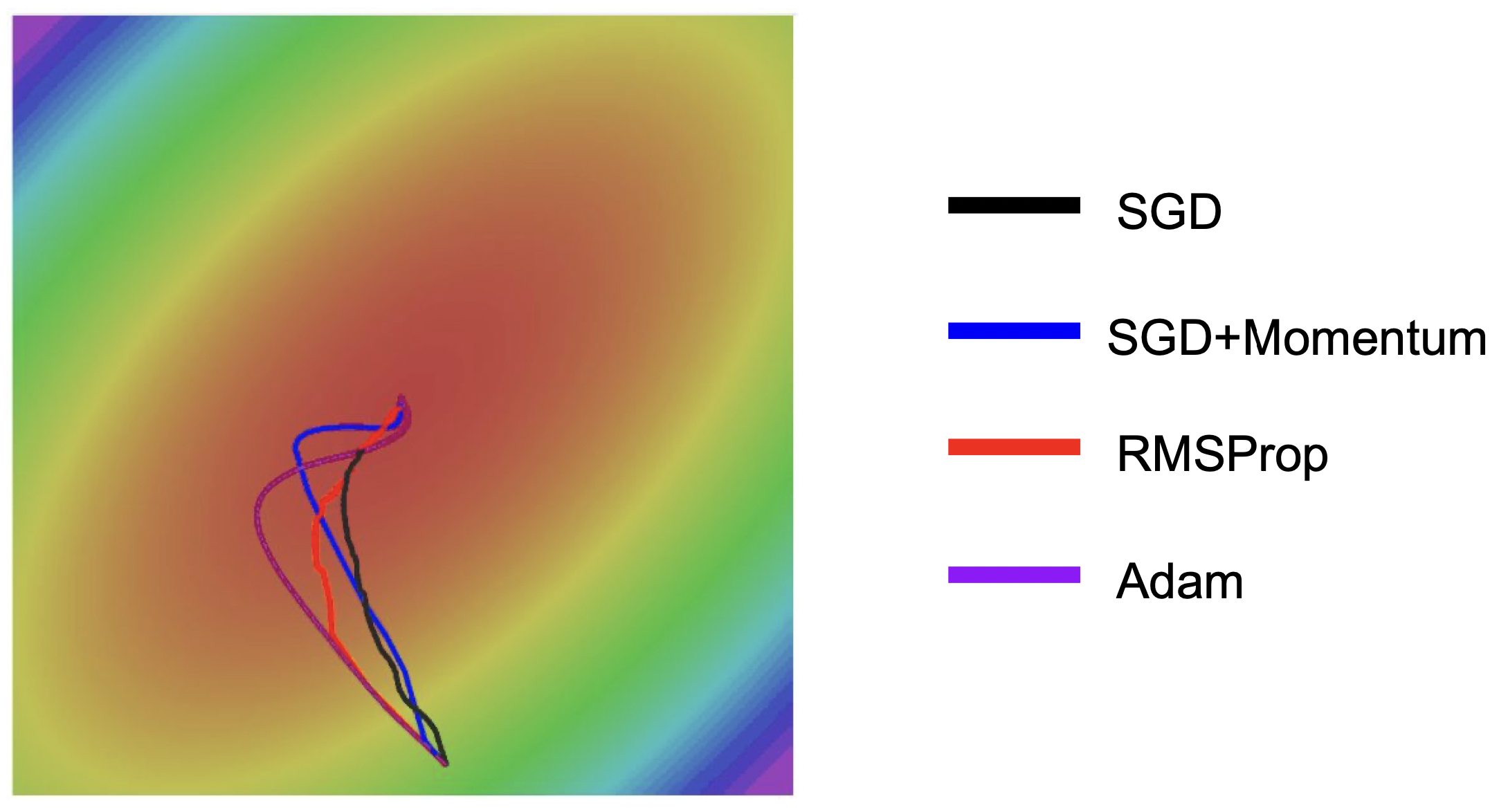
二阶优化器
深度学习的优化算法主要是基于梯度的,即一阶算法,都需要经过反向传播计算每个参数的梯度,根据梯度方向和大小作参数更新。以上全部为一阶算法。
二阶算法要用到函数的二阶信息,即 Hessian 矩阵。深度学习由于参数 \(N\) 很多,矩阵规模 \(O(N^2)\) 很大,计算代价更是高(要用矩阵求逆,复杂度为 \(O(N^3)\)),一般无法应用到深度学习中,牛顿法是一个例子。
少数降低计算代价的二阶算法可以应用到深度学习中,如 L-BFGS(Limited memory BFGS),它将牛顿法中求矩阵逆改为求近似的 BGFS 算法(属于拟牛顿法),同时也不一次求整个矩阵逆的近似(即 limited memory),极大降低了计算代价。原理不再介绍。
六、损失函数
这里重点考虑的不是加在模型输出与真实值之间的那个原始损失函数的选取。一般来说,分类问题用交叉熵损失,回归问题用平方损失就够了。本节讨论加在损失函数后面的正则项。很多科研工作就是设计了针对某场景的正则项,对该场景起到了特定的作用,我们也不讨论。只讨论一些可当作通用的深度学习 trick 的正则化方法,对于任何模型都可以施加的 trick。
本章统一记号如下,其中 \(\lambda > 0\) 为正则化超参数,用于调整正则化的强度;\(\theta\) 为模型参数。
\[L(\theta) = \frac1N \sum_{i=1}^N L_i (f(\mathbf{x}_i; \theta), y_i) + \lambda R(\theta)\]以下讨论的所有正则化方法都是为了缓解过拟合,详见本文最后一章。
L2 正则化又称权重衰减(weight decay)、岭回归。
\[R(\theta) = \frac12 \sum_{w} w^2\]注意,通常只对权重、不对 bias 作正则化。
可以证明,在损失函数中加入 L2 正则项等价于在更新参数的梯度下降公式中加入下式最后一项(其中 \(\eta\) 为学习率,\(\lambda\) 为 L2 正则化系数): \(w := w - \eta g - \eta \lambda w\) 这一项可以与前面的 \(w\) 合并:\((1-\eta\lambda) w\),形式上看就是让权重衰减了一下再梯度下降,这也是 L2 正则化被称为权重衰减的原因。
L1 正则化又称 Lasso(套索)算法,它将对权重 2 范数的约束换为了 1 范数。
\[R(\theta) = \sum_{w} \mid w\mid\]它也限制了所有权重的大小,但使用 1 范数倾向于让一些权重直接置 0(稀疏化),起到了特征选择的作用。还有一些更花哨的 L1 正则化,如 Adaptive Lasso, Group Lasso,可参考专门讲 Lasso 的《Statistics for High-Dimensional Data: Methods Theory and Applications》一书。
L1 和 L2 相加的正则化称为弹性网络(Elastic Net),其中 \(\beta\) 为平衡超参数。
\[R(\theta) = \sum_{w} (\beta w^2 + \mid w\mid)\]还有平滑(smooth)L1 损失,像是 L1 和 L2 的分段组合。
\[R(\theta) = sum_{w} sl(w), sl(w) = \frac12 w^2, \mid w \mid <1, \mid w\mid-\frac, \mid w\mid>1\]七、超参数优化
深度学习有很多超参数(hyperparameters):
- 网络参数:神经元数量,卷积核大小,卷积层步长与填充值等;
- 优化参数:学习率,batch_size,优化器的其他参数;
- 正则化超参数:正则项系数、Dropout 的丢弃概率;
网络参数关系到模型大小,通常是最初设定好的。batch_size 也是根据计算资源能开大则开大。除此之外,最重要的超参数是学习率。
我们需要选择合适的超参数,使模型在这组超参数下训练效果最好,此过程称为超参数优化。超参数优化遵循交叉验证(cross-validation)的科学实验原则:参考的测试集不应为真正的测试集,而是验证集(validation set),它通常是从训练集中分离出的一部分。
训练效果主要参考 loss 和准确率等指标随迭代的曲线,所谓训练效果好有以下几个判断标准:
- loss 有比较显著、稳定的下降;或者看参数更新幅度的比值是否过大或过小;
- 收敛时 loss 足够小,指标足够好;
- 训练集和验证集上指标差距不大(否则为过拟合)。
超参数优化的通常策略是由粗到细(coarse to fine):
- 先手动地超参数优化用于粗选范围,即用肉眼观察曲线,监视训练过程,边看边调参;
- 再由自动的算法在该范围内精细搜索,算法规定了 “好坏” 判断机制和搜索下一组待试验的超参数值的方法。
下面分别介绍它们。
手动粗选范围
手动选择不必多作介绍,这就是传说中的深度学习 “调参”,需要人有很多训练深度学习模型的经验,从业者有时也被戏称为 “调参师”。
手动选择最简单的做法是每选一组超参数就从头开始跑一下。一个更省时间的做法是在同一个训练过程中使用各种超参数(例如每个 epoch 都换一组超参数),仅观察 1 个 epoch 下 loss 的下降情况,但这样也要承担不准的风险。
手动选择只需寻找各超参数的大体的合适范围,剩下精细搜索人很难胜任,可以交给自动的搜索算法完成。
参数搜索算法
遍历所有的超参数组合计算代价是巨大的,通常使用搜索算法,重点放在如何下一组待试验的超参数值上。常用的有:
- 网格搜索(grid search):将超参数范围按一定间隔划分,只考虑网格上的点。搜索策略有很多,如深度优先、广度优先以及一些启发式算法等(参考算法课程);
- 随机搜索(random search):每个超参数指定其范围内的一个分布,每次从分布中抽样。据说比网格搜索更高效、精细。 Random Search for Hyper-Parameter Optimization
过拟合问题总论
本章将统一地详细讨论模型的过拟合问题,这是深度学习训练的一个重要议题。
欠拟合(Underfitting)是模型没有充分探求训练集的规律,导致训练集和测试集效果都差。过拟合(Overfitting)是过分探求了训练集上的规律,导致虽然训练集效果好,但测试集效果差,模型泛化能力差。这两种情况都不是训练想得到的。
过拟合、欠拟合的判断
首先给出在训练过程中判断模型是否过拟合或欠拟合。
对于一个给定的模型,判断过拟合与否主要是通过学习曲线(learning curve),见下图,此图的横坐标是训练的轮数。下图是正常状态下画出的。还有两种不正常状态:我称为总是欠拟合、总是过拟合。 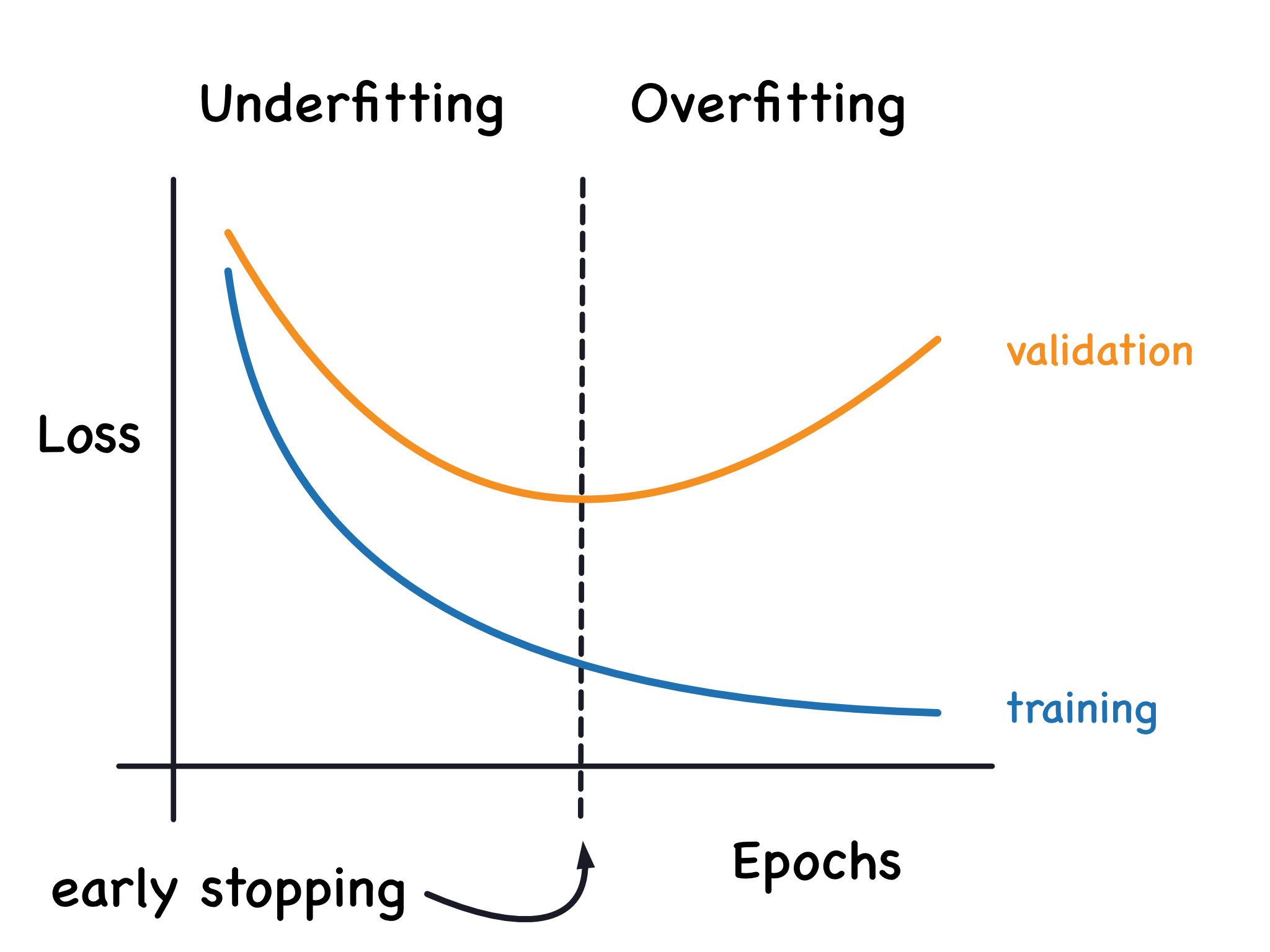
请注意,这里的 “测试集 loss” 指验证集。测试数据是只能用于最终的测试,不可以辅助模型训练。

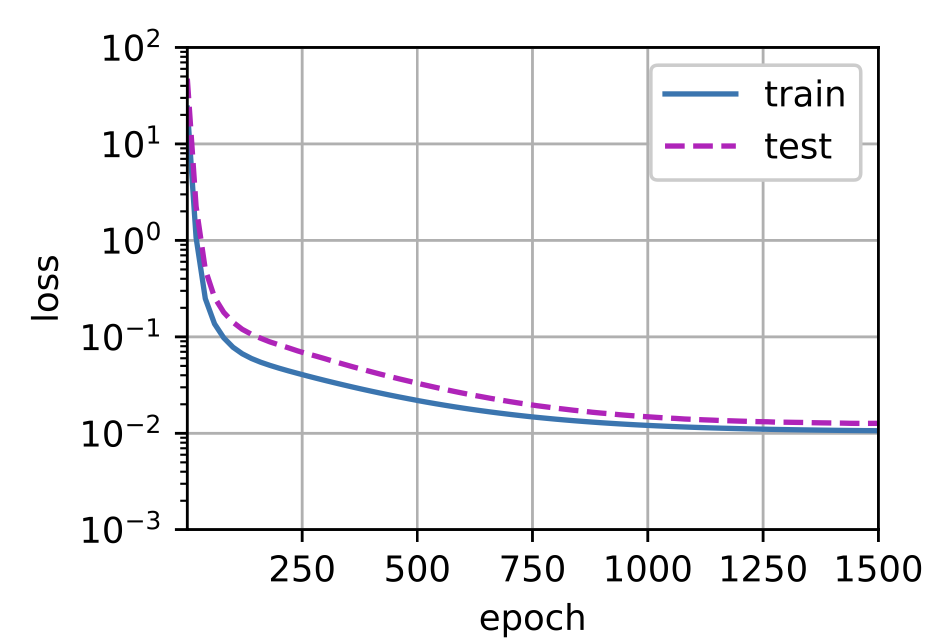

以上分别对应三种情况:
- 总是欠拟合:两个 loss 都非常大,降不下去;
- 正常:两个 loss 都能充分下降,呈现出前面学习曲线的模样,有一个临界点:之前的是欠拟合,之后就慢慢变成过拟合了;
- 总是过拟合:训练 loss 能充分下降,但测试 loss 总是较大;而且之后训练很多 epoch 也不见得拉低二者的差距。
解决过拟合、欠拟合
在训练时判断出欠拟合与过拟合后,就该解决了。如果学习曲线出现以上“总是欠拟合”、“总是过拟合”,就将学习曲线变“正常”。
欠拟合和过拟合与模型复杂度、训练数据量有关。它们的关系如下图:
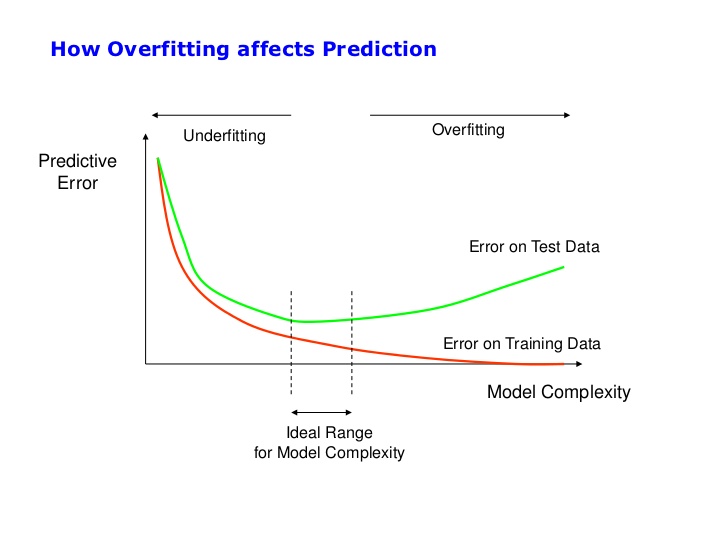
模型复杂度越高,越容易“总是过拟合”。反之,模型复杂度太低,则容易“总是欠拟合”。这里的模型复杂度是相对于训练数据量而言的,即越复杂的模型需要越大的数据量,若不匹配则会出现这两种情况。
解决“总是欠拟合”,只需提高模型复杂度,设计更复杂的模型即可,例如增加神经元等方法。这一点很容易做到,欠拟合的情况是容易处理的,因此也无需专门防止欠拟合的方法。
通过减少训练数据量不能解决欠拟合,一个“偷懒”的模型效果不可能好!而且这也是很蠢的行为,有数据为何不用呢?只需稍一动手把模型搞复杂点即可。
解决“总是过拟合”,一个思路是收集更多的数据,提高数据量,但实际很难做到,训练数据量一般是固定的。另一思路就是降低模型复杂度,当然可以砍掉一部分神经元,但通常我们不想把辛辛苦苦设计的模型直接砍掉,这样太生硬,就想出一些花招,包括:
- 正则化(weight decay 等);
- Dropout;
- Batch Normalization;
- 数据增强;
- 集成学习;
- 预训练 + 微调;
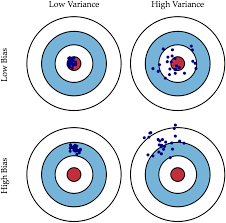
用“偏差-方差”理论来解释,这张图有两个维度:偏差(bias)和方差(variance),理想状态是低偏差和低方差。数据量越大,方差越小;模型越复杂,偏差越小。“总是欠拟合”对应高偏差,“总是过拟合”对应高方差和低偏差。
学习曲线“正常”化之后,还是需要找到临界时刻。临界时刻即测试 loss 开始升高时,继续训练会导致过拟合,令训练停在临界时刻的策略称为早停(early stopping)。